
Just like software engineering, best practices for serverless applications advise keeping functions small and focused on a single task, aka “do one thing and do it well”. Small single-purpose functions are easier to develop, test and debug. 👍
But what happens when you need execute multiple asynchronous tasks (implemented as separate functions) from an incoming event, like an API request? 🤔
Functions Calling Functions?
Functions can invoke other functions directly, using asynchronous calls through the client SDK. This works at the cost of introducing tighter coupling between functions, which is generally avoided in software engineering! Disadvantages of this approach include…
- Functions which call other functions can be more difficult to test. Test cases needs to mock out the client SDK to remove side-effects during unit or integration tests.
- It can lead to repetitive code if you want to fire multiple tasks with the same event. Each invocation needs to manually handle error conditions and re-tries on network or other issues, which complicates the business logic.
- Modifying the functions being invoked cannot be changed dynamically. The function doing the invoking has to be re-deployed with updated code.
Some people have even labelled “functions calling functions” an anti-pattern in serverless development! 😱
Most common Serverless mistake?
— Paul Johnston - current focus: moving electrons (@PaulDJohnston) January 15, 2019
Functions calling other functions
Why do people make this mistake?
Because people assume they should build functions like microservices and then use them in a similar way.
Causes no end of problems
Hmmm… so what should we do?
Apache OpenWhisk has an awesome feature to help with this problem, triggers and rules! 👏
OpenWhisk Triggers & Rules
Triggers and Rules in OpenWhisk are similar to the Observer pattern from software engineering.
Users can fire “events” in OpenWhisk by invoking a named trigger with parameters. Rules are used to “subscribe” actions to all events for a given trigger name. Actions are invoked with event parameters when a trigger is fired. Multiple rules can be configured to support multiple “listeners” to the same trigger events. Event senders are decoupled from event receivers.
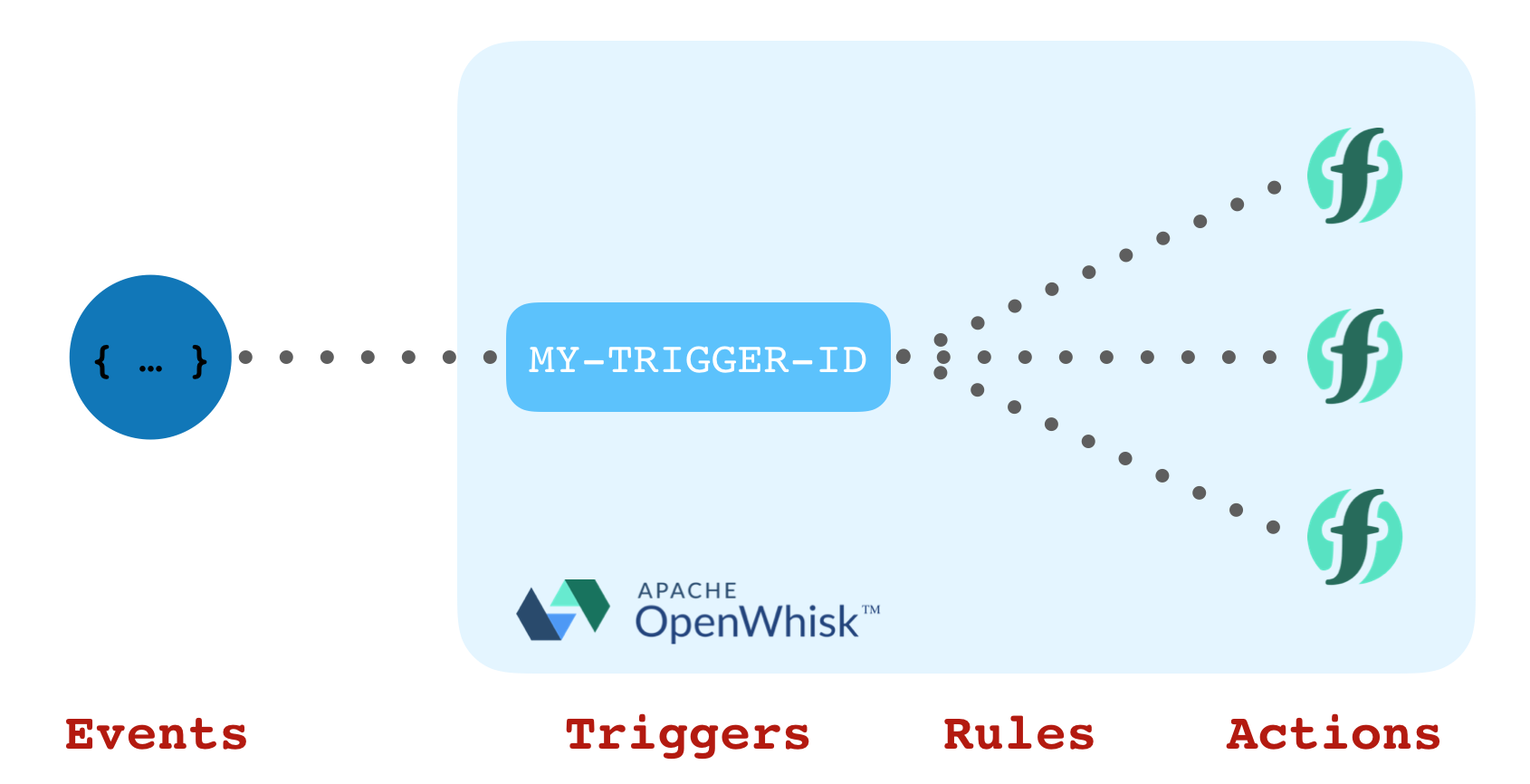
Developers using OpenWhisk are most familiar with triggers when used with feed providers. This is used to subscribe actions to external event sources. The feed provider is responsible for listening to the event source and automatically firing trigger events with event details.
But triggers can be fired manually from actions to provide custom event streams! 🙌
const openwhisk = require('openwhisk')
const params = {msg: 'event parameters'}
// replace code like this...
const result = await ow.actions.invoke({name: "some-action", params})
// ...with this
const result = await ow.triggers.invoke({name: "some-trigger", params})
This allows applications to move towards an event-driven architecture and promotes loose-coupling between functions with all the associated benefits for testing, deployment and scalability. 👌
creating triggers
Triggers are managed through the platform API. They can be created, deleted, retrieved and fired using HTTP requests. Users normally interact with triggers through the CLI or platform SDKs.
Triggers can be created using the following CLI command.
wsk trigger create <TRIGGER_NAME>
default parameters
Triggers support default parameters like actions. Default parameters are stored in the platform and included in all trigger events. If the event object includes parameters with the same key, default parameter values are ignored.
wsk trigger create <TRIGGER_NAME> -p <PARAM> <PARAM_VALUE> -p <PARAM_2> <PARAM_VALUE> ...
binding triggers to actions with rules
Rules bind triggers to actions. When triggers are fired, all actions connected via rules are invoked with the trigger event. Multiple rules can refer to the same trigger supporting multiple listeners to the same event.
Rules can also be created using the following CLI command.
wsk rule create RULE_NAME TRIGGER_NAME ACTION_NAME
Tools like The Serverless Framework and wskdeploy allow users to configure triggers and rules declaratively through YAML configuration files.
firing triggers
The JS SDK can be used to fire triggers programatically from applications.
const openwhisk = require('openwhisk')
const name = 'sample-trigger'
const params = {msg: 'event parameters'}
const result = ow.triggers.invoke({name, params})
CLI commands (wsk trigger fire) can fire triggers manually with event parameters for testing.
wsk trigger fire sample-trigger -p msg "event parameters"
activation records for triggers
Activation records are created for trigger events. These activation records contain event parameters, rules fired, activations ids and invocation status for each action invoked. This is useful for debugging trigger events when issues are occurring.
$ wsk trigger fire sample-trigger -p hello world
ok: triggered /_/sample-trigger with id <ACTIVATION_ID>
$ wsk activation get <ACTIVATION_ID>
ok: got activation <ACTIVATION_ID>
{
...
}
The response.result property in the activation record contains the fired trigger event (combining default and event parameter values).
Rules fired by the trigger are recorded in activation records as the JSON values under the logs parameter.
{
"statusCode": 0,
"success": true,
"activationId": "<ACTION_ACTIVATION_ID>",
"rule": "<RULE_NAME>",
"action": "<ACTION_NAME>"
}
Activation records are only generated when triggers have enabled rules with valid actions attached
Example - WC Goal Bot
This is great in theory but what about in practice?
Goal Bot was a small serverless application I built in 2018 for the World Cup. It was a Twitter bot which tweeted out all goals scored in real-time. The application used the “actions connected via triggers events” architecture pattern. This made development and testing easier and faster.
⚽️ GOAL ⚽️
— WC 2018 Goal Bot (@WC2018_Goals) July 7, 2018
👨 Harry MAGUIRE (🏴 ) @ 30'. 👨
🏟 Sweden 🇸🇪 (0) v England 🏴 (1) 🏟#WorldCup
This function has two functions goals and twitter.
goals was responsible for detecting new goals scored using an external API. When invoked, it would retrieve all goals currently scored in the World Cup. Comparing the API response to a previous cached version calculated new goals scored. This function was connected to the alarm event source to run once a minute.
twitter was responsible for sending tweets from the @WC_Goals account. Twitter’s API was used to create goal tweets constructed from the event parameters.
Goal events detected in the goals function need to be used to invoke the twitter function.
Rather than the goals function invoke the twitter function directly, a trigger event (goal) was fired. The twitter function was bound to the goal trigger using a custom rule.
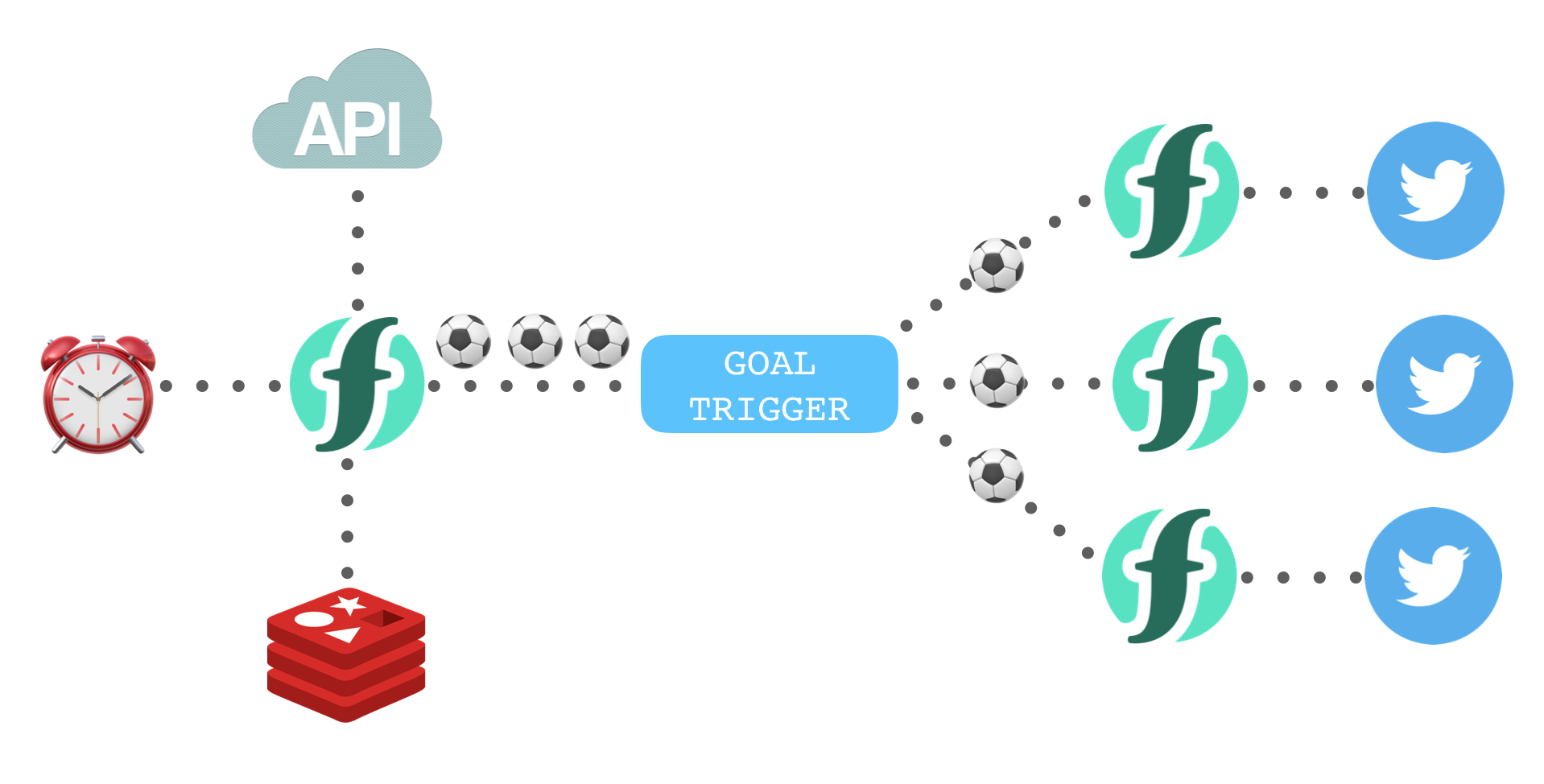
De-coupling the two tasks in my application (checking for new goals and creating tweets) using triggers and rules had the following benefits…
-
The
goalsfunction could be invoked in testing without tweets being sent. By disabling the rule binding thetwitterfunction to the trigger, the goals function can fire events without causing side-effects. -
Compared to having a “mono-function” combining both tasks, splitting tasks into functions means the
twitterfunction can be tested with manual events, rather than having to manipulate the database and stub API responses to generate the correct test data. -
It would also be easy to extend this architecture with additional notification services, like slack bots. New notification services could be attached to the same trigger source with an additional rule. This would not require any changes to the
goalsortwitterfunctions.
Triggers versus Queues
Another common solution to de-coupling functions in serverless architectures is using message queues.
Functions push events in external queues, rather than invoking triggers directly. Event sources are responsible for firing the registered functions with new messages. Apache OpenWhisk supports Kafka as an event source which could be used with this approach.
How does firing triggers directly compare to pushing events into an external queue (or other event source)?
Both queues and triggers can be used to achieve the same goal ("connect functions via events") but have different semantics. It is important to understand the benefits of both to choose the most appropriate architecture for your application.
benefits of using triggers against queues
Triggers are built into the Apache OpenWhisk platform. There is no configuration needed to use them. External event sources like queues need to be provisioned and managed as additional cloud services.
Trigger invocations are free in IBM Cloud Functions. IBM Cloud Functions charges only for execution time and memory used in functions. Queues will incur additional usage costs based on the service’s pricing plan.
disadvantages of using triggers against queues
Triggers are not queues. Triggers are not queues. Triggers are not queues. 💯
If a trigger is fired and no actions are connected, the event is lost. Trigger events are not persisted until listeners are attached. If you need event persistence, message priorities, disaster recovery and other advanced features provided by message queues, use a message queue!
Triggers are subject to rate limiting in Apache OpenWhisk. In IBM Cloud Functions, this defaults to 1000 concurrent invocations and 5000 total invocations per namespace per minute. These limits can be raised through a support ticket but there are practical limits to the maximum rates allowed. Queues have support for much higher throughput rates.
External event providers are also responsible for handling the retries when triggers have been rate-limited due to excess events. Invoking triggers manually relies on the invoking function to handle this. Emulating retry behaviour from an event provider is impractical due to costs and limits on function duration.
Other hints and tips
Want to invoke an action which fires triggers without setting off listeners?
Rules can be dynamically disabled without having to remove them. This can be used during integration testing or debugging issues in production.
wsk rule disable RULE_NAME
wsk rule enable RULE_NAME
Want to verify triggers are fired with correct events without mocking client libraries?
Trigger events are not logged unless there is at least one enabled rule. Create a new rule which binds the /whisk.system/utils/echo action to the trigger. This built-in function just returns input parameters as the function response. This means the activation records with trigger events will now be available.
conclusion
Building event-driven serverless applications from loosely-coupled functions has numerous benefits including development speed, improved testability, deployment velocity, lower costs and more.
Decomposing “monolithic” apps into independent serverless functions often needs event handling functions to trigger off multiple backend operations, implemented in separate serverless functions. Developers unfamiliar with serverless often resort to direct function invocations.
Whilst this works, it introduces tight coupling between those functions, which is normally avoided in software engineering. This approach has even been highlighted as a “serverless” anti-pattern.
Apache OpenWhisk has an awesome feature to help with this problems, triggers and rules!
Triggers provide a lightweight event firing mechanism in the platform. Rules bind actions to triggers to automate invoking actions when events are fired. Applications can fire trigger events to invoke other operations, rather than using direct invocations. This keeps the event sender and receivers de-coupled from each other. 👏