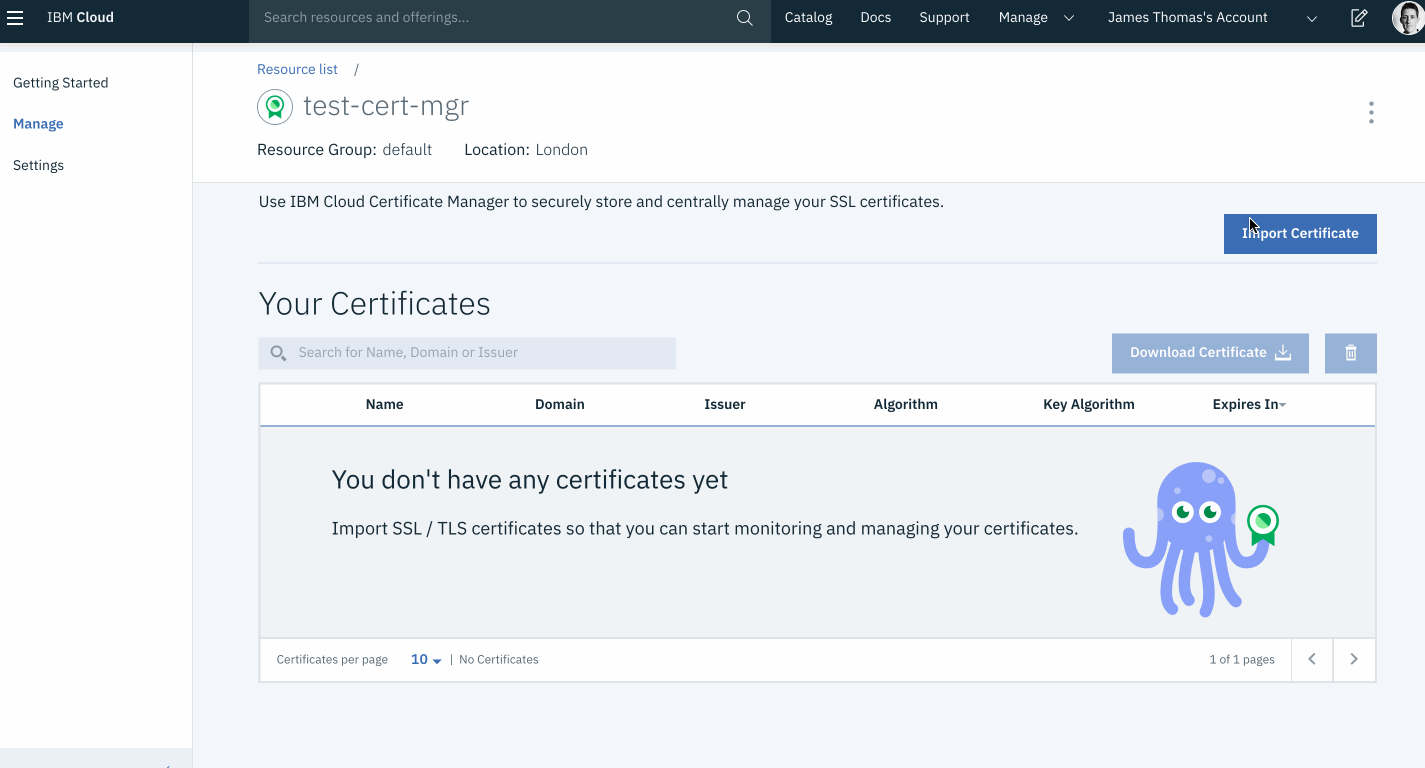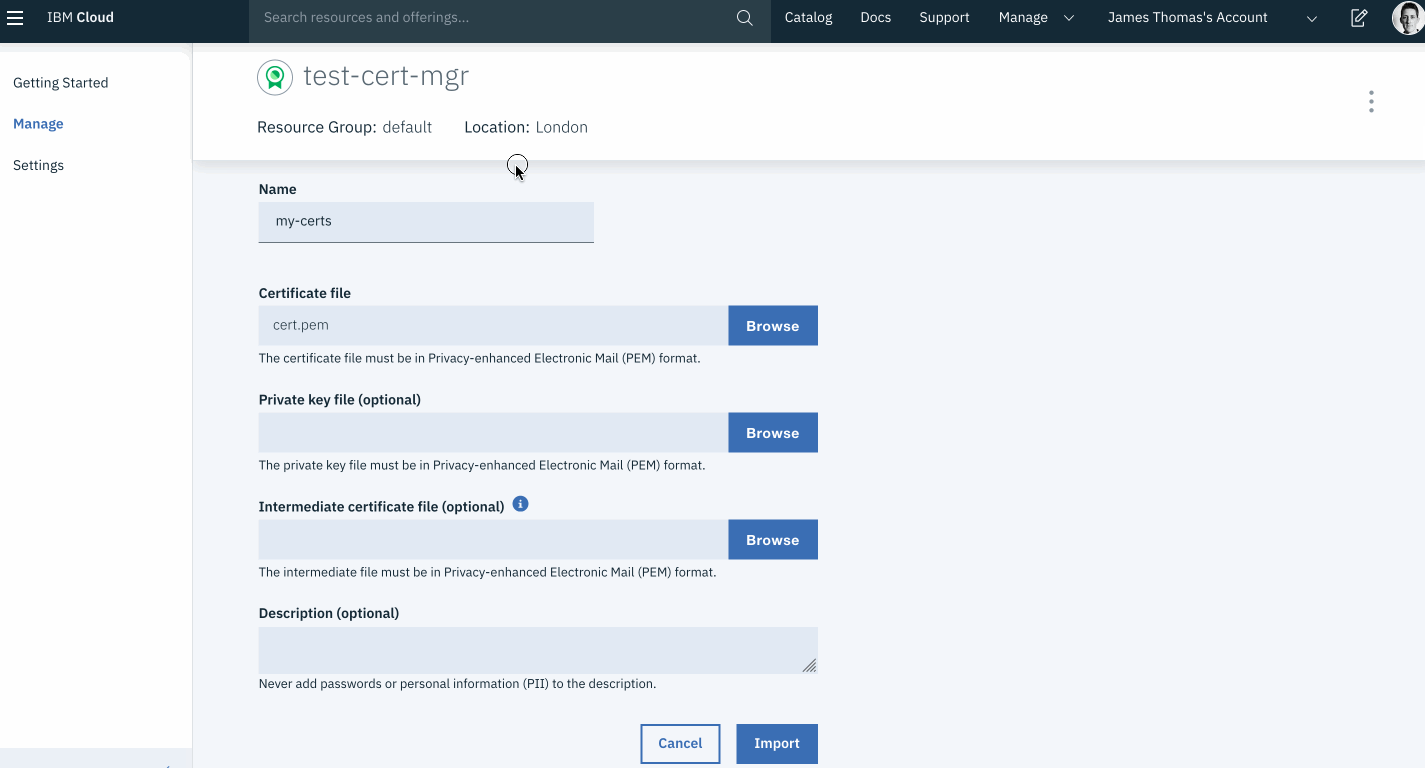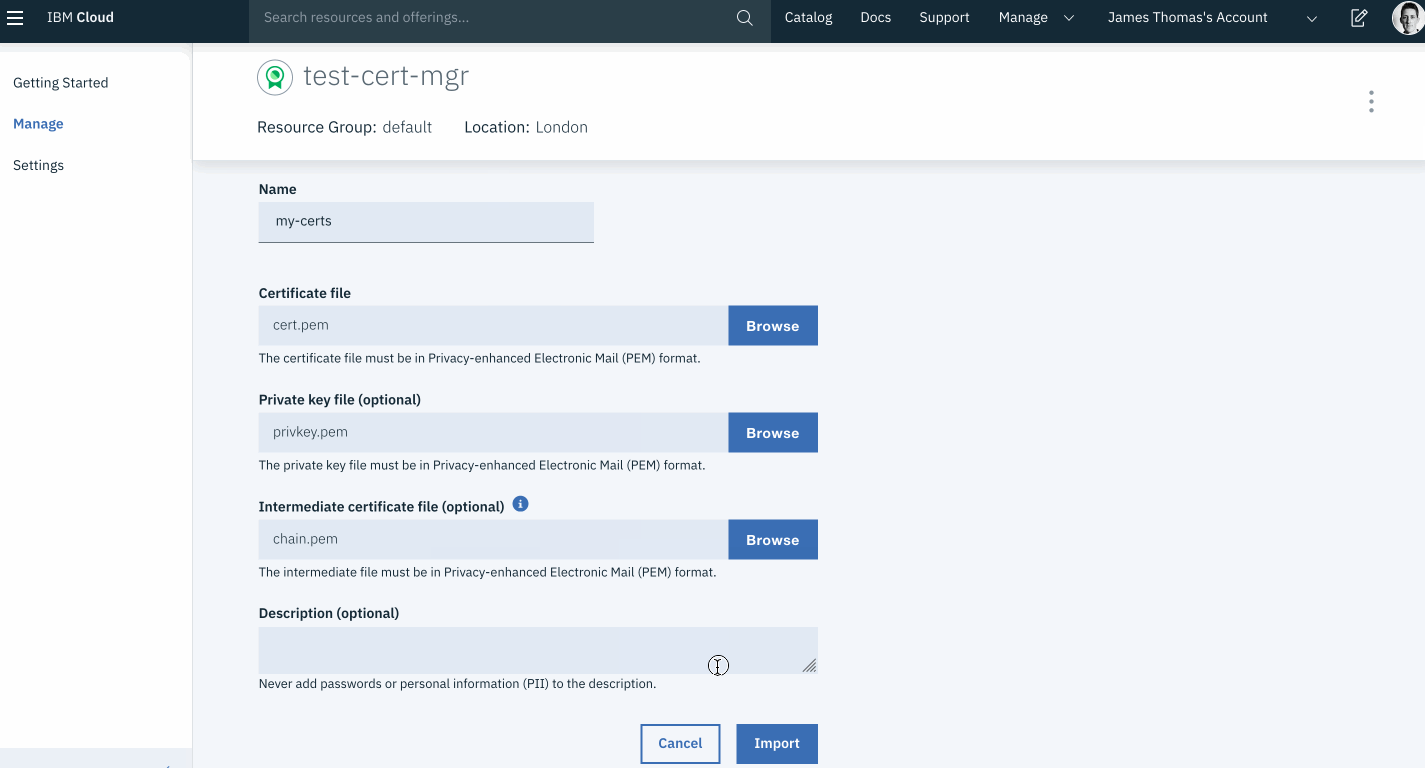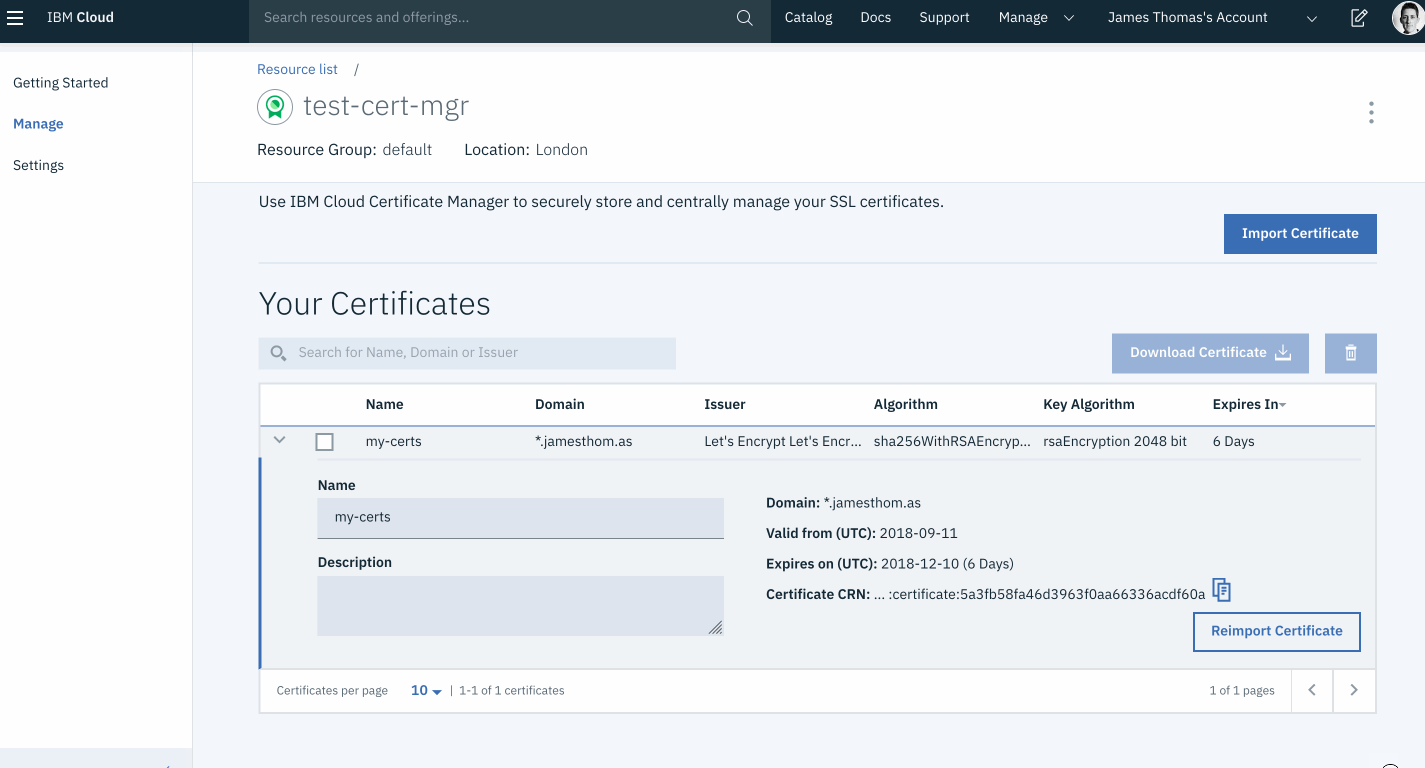
This week, I came across an interesting problem when building HTTP APIs on IBM Cloud Functions.
How can Apache OpenWhisk Web Actions, implemented using action sequences, handle application errors that need the sequence to stop processing and a custom HTTP response to be returned?
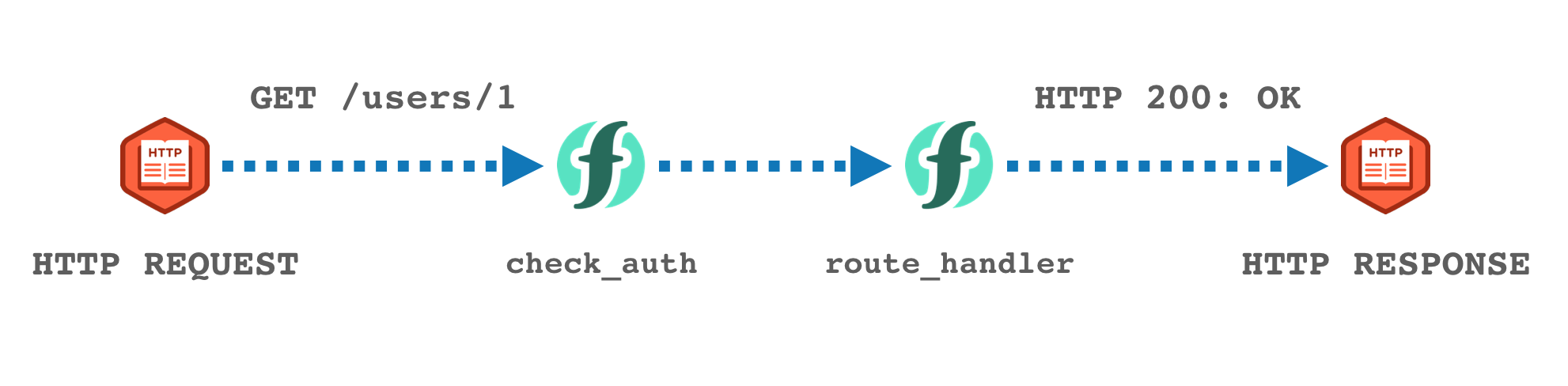
This came from wanting to add custom HTTP authentication to existing Web Actions. I had decided to enhance existing Web Actions with authentication using action sequences. This would combine a new action for authentication validation with the existing API route handlers.
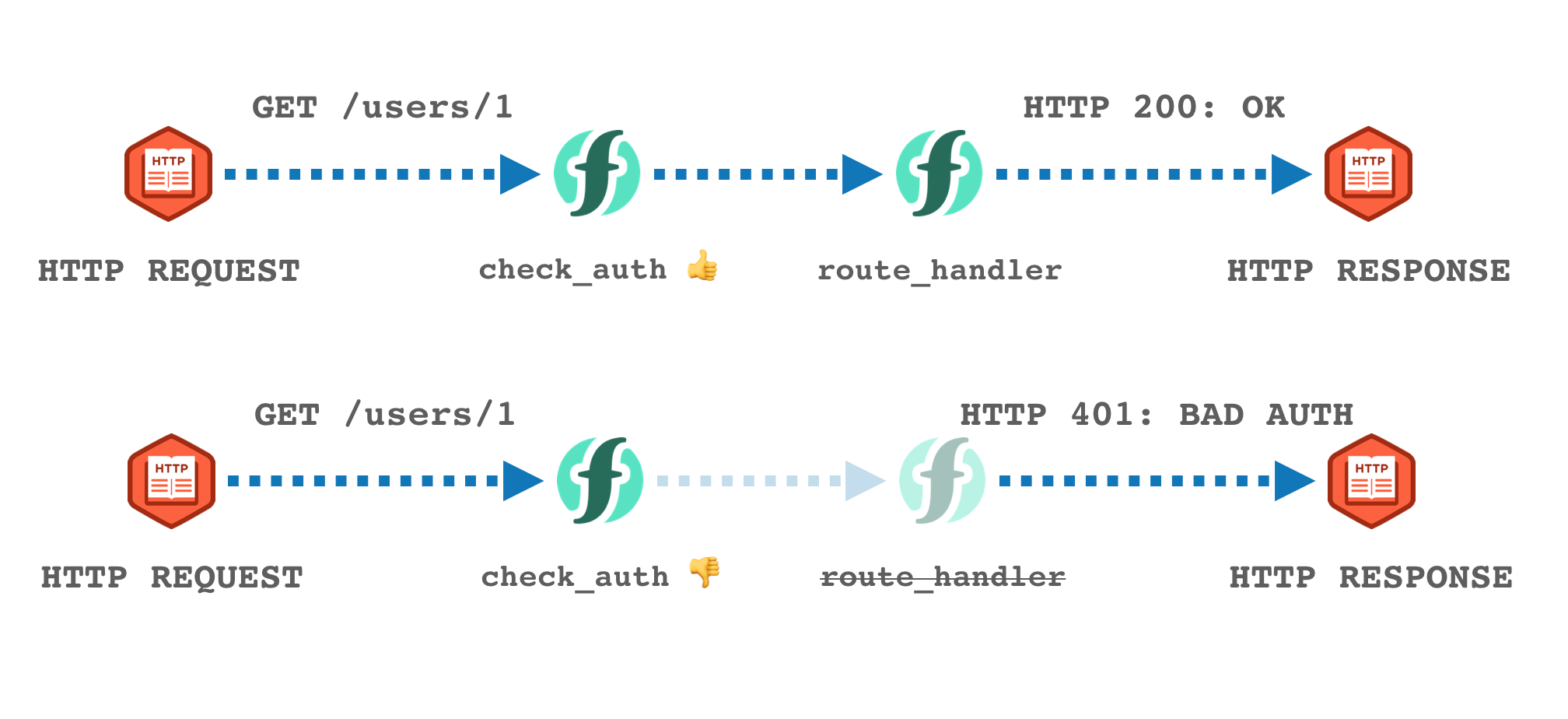
When the HTTP authentication is valid, the authentication action becomes a ”no-op”, which passes along the HTTP request to the route handler action to process as normal.
But what happens when authentication fails?
The authentication action needs to stop request processing and return a HTTP 401 response immediately.
Does Apache OpenWhisk even support this?
Fortunately, it does (phew) and I eventually worked out how to do this (based on a combination of re-reading documentation, the platform source code and just trying stuff out!).
Before explaining how to return custom HTTP responses using web action errors in sequences, let’s review web actions, actions sequences and why developers often use them together…
Web Actions
Web Actions are OpenWhisk actions that can be invoked using external HTTP requests.
Incoming HTTP requests are provided as event parameters. HTTP responses are controlled using attributes (statusCode, body, headers) in the action result.
Web Actions can be invoked directly, using the platform API, or connected to API Gateway endpoints.
example
Here is an example Web Action that returns a static HTML page.
Web actions can be exported from any existing action by setting an annotation.
This is handled automatically by CLI using the —web configuration flag when creating or updating actions.
1
wskactioncreateACTION_NAMEACTION_CODE--webtrue
Action Sequences
Multiple actions can be composed together into a “meta-action” using sequences.
Sequence configuration defines a series of existing actions to be called sequentially upon invocation. Actions connected in sequences can use different runtimes and even be sequences themselves.
Input events are passed to the first action in the sequence. Action results from each action in the sequence are passed to the next action in the sequence. The response from the last action in the sequence is returned as the action result.
example
Here is a sequence (mySequence) composed of three actions (action_a, action_b, action_c).
Invoking mySequence will invoke action_a with the input parameters. action_b will be invoked with the result from action_a. action_c will be invoked with the result from action_b. The result returned by action_c will be returned as the sequence result.
Web Actions from Action Sequences
Using Action Sequences as Web Actions is a useful pattern for externalising common HTTP request and response processing tasks into separate serverless functions.
These common actions can be included in multiple Web Actions, rather than manually duplicating the same boilerplate code in each HTTP route action. This is similar to the ”middleware” pattern used by lots of common web application frameworks.
Web Actions using this approach are easier to test, maintain and allows API handlers to implement core business logic rather than lots of duplicate boilerplate code.
authentication example
In my application, new authenticated web actions were composed of two actions (check_auth and the API route handler, e.g. route_handler).
Here is an outline of the check_auth function in Node.js.
1234567891011
constcheck_auth=(params)=>{constheaders=params.__ow_headersconstauth=headers['authorization']if(!is_auth_valid(auth)){// stop sequence processing and return HTTP 401?}// ...else pass along request to next sequence actionreturnparams}
The check_auth function will inspect the HTTP request and validate the authorisation token. If the token is valid, the function returns the input parameters untouched, which leads the platform the invoke the route_handler to generate the HTTP response from the API route.
But what happens if the authentication is invalid?
The check_auth action needs to return a HTTP 401 response immediately, rather than proceeding to the route_handler action.
handling errors - synchronous results
Sequence actions can stop sequence processing by returning an error. Action errors are indicated by action results which include an “error” property or return rejected promises (for asynchronous results). Upon detecting an error, the platform will return the error result as the sequence action response.
If check_auth returns an error upon authentication failures, sequence processing can be halted, but how to control the HTTP response?
Error responses can also control the HTTP response, using the same properties (statusCode, headers and body) as a successful invocation result, with one difference: those properties must be the children of the error property rather than top-level properties.
This example shows the error result needed to generate an immediate HTTP 401 response.
123456
{"error":{"statusCode":401,"body":"Authentication credentials are invalid."}}
In Node.js, this can be returned using a synchronous result as shown here.
1234567891011
constcheck_auth=(params)=>{constheaders=params.__ow_headersconstauth=headers['authorization']if(!is_auth_valid(auth)){constresponse={statusCode:401,body:"Authentication credentials are invalid."}return{error:response}}returnparams}
handling errors - using promises
If a rejected Promise is used to return an error from an asynchronous operation, the promise result needs to contain the HTTP response properties as top-level properties, rather than under an error parent. This is because the Node.js runtime automatically serialises the promise value to an error property on the activation result.
1234567891011
constcheck_auth=(params)=>{constheaders=params.__ow_headersconstauth=headers['authorization']if(!is_auth_valid(auth)){constresponse={statusCode:401,body:"Authentication credentials are invalid."}returnPromise.reject(response)}returnparams}
conclusion
Creating web actions from sequences is a novel way to implement the “HTTP middleware” pattern on serverless platforms. Surrounding route handlers with pre-HTTP request modifier actions for common tasks, allows route handlers to remove boilerplate code and focus on the core business logic.
In my application, I wanted to use this pattern was being used for custom HTTP authentication validation.
When the HTTP request contains the correct credentials, the request is passed along unmodified. When the credentials are invalid, the action needs to stop sequence processing and return a HTTP 401 response.
Working out how to do this wasn’t immediately obvious from the documentation. HTTP response parameters need to included under the error property for synchronous results. I have now opened a PR to improve the project documentation about this.
This was based on my experience building a new event provider for Apache OpenWhisk, which led me to prototype an easier way to add event sources to platform whilst cutting down on the boilerplate code required.
Slides from the talk are here and there’s also a video recording available.
This blog post is overview of what I talked about on the call, explaining the background for the project and what was built. Based on positive feedback from the community, I have now open-sourced bothcomponents of the experiment and will be merging it back upstream into Apache OpenWhisk in future.
pluggable event providers - why?
At the end of last year, I was asked to prototype an S3-compatible Object Store event source for Apache OpenWhisk. Reviewing the existing event providers helped me understand how they work and what was needed to build a new event source.
This led me to an interesting question…
Why do we have relatively few community contributions for event sources?
Most of the existing event sources in the project were contributed by IBM. There hasn’t been a new event source from an external community member. This is in stark contrast to additional platform runtimes. Support for PHP, Ruby, DotNet, Go and many more languages all came from community contributions.
Digging into the source code for the existing feed providers, I came to the following conclusions….
Trigger feed providers are not simple to implement.
Documentation how existing providers work is lacking.
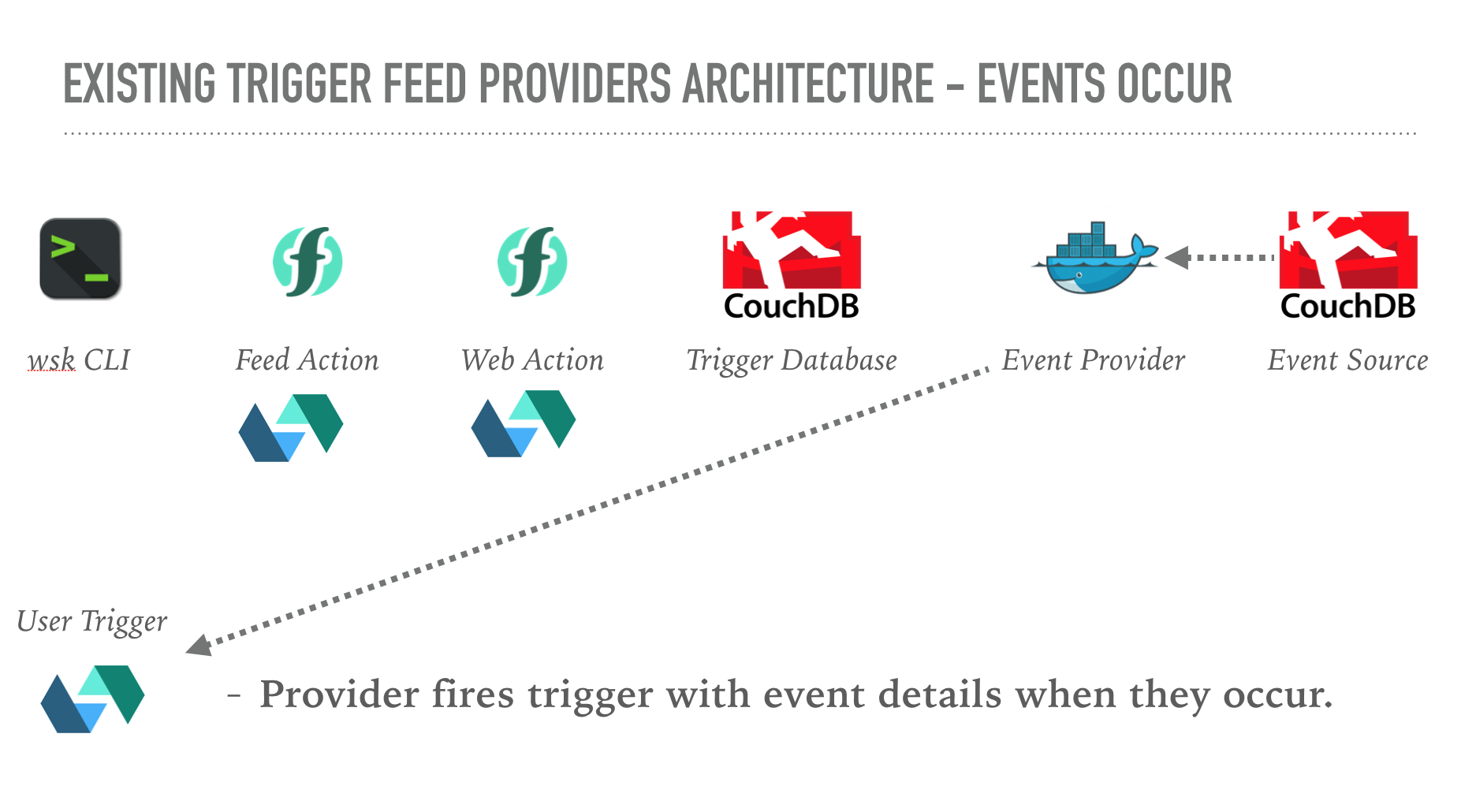
Feed providers can feel a bit like magic to users. You call the wsk CLI with a feed parameter and that’s it, the platform handles everything else. But what actually happens to bind triggers to external event sources?
Let’s start by explaining how trigger feeds are implemented in Apache OpenWhisk, before moving onto my idea to make contributing new feed providers easier.
how trigger feeds work
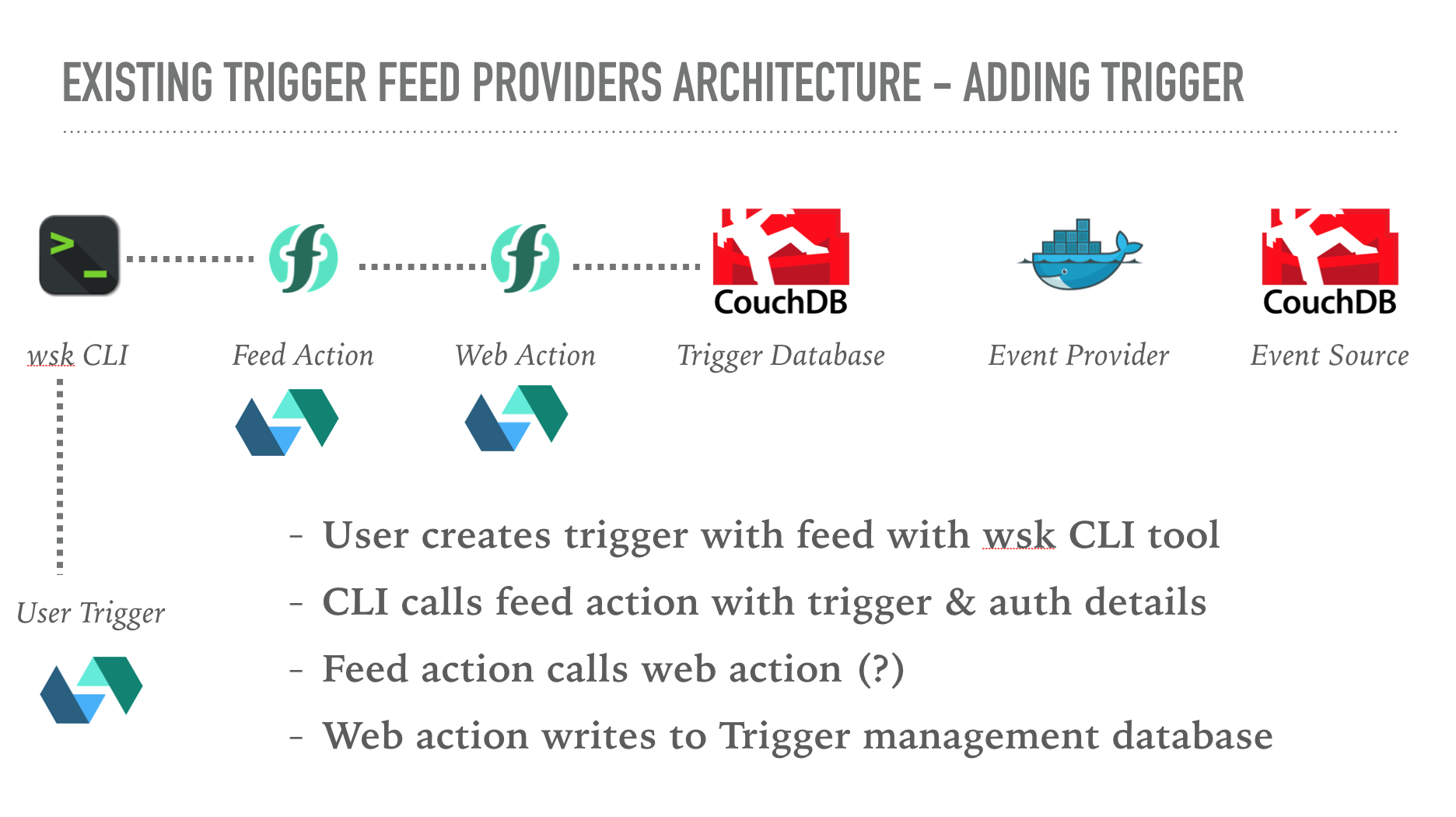
Users normally interact with trigger feeds using the wsk CLI. Whilst creating a trigger, the feed parameter can be included to connect that trigger to an external event source. Feed provider options as provided as further CLI parameters.
But what are those trigger feed identifiers used with the feed parameter?
It turns out they are just normal actions which have been shared in a public package!
The CLI creates the trigger (using the platform API) and then invokes the referenced feed action. Invocation parameters include the following values used to manage the trigger feed lifecycle.
Custom feed parameters from the user are also included in the event parameters.
This is the entire interaction of the platform with the feed provider.
Providers are responsible for the full management lifecycle of trigger feed event sources. They have to maintain the list of registered triggers and auth keys, manage connections to user-provided event sources, fire triggers upon external events, handle retries and back-offs in cases of rate-limiting and much more.
Feed providers used with a trigger are stored as custom annotations. This allows the CLI to call the same feed action to stop the event binding when the trigger is deleted.
trigger management
Reading the source code for the existing feed providers, nearly all of the code is responsible for handling the lifecycle of trigger management events, rather than integrating with the external event source.
Despite this, all of the existing providers are in separate repositories and don’t share code explicitly, although the same source files have been replicated in different repos.
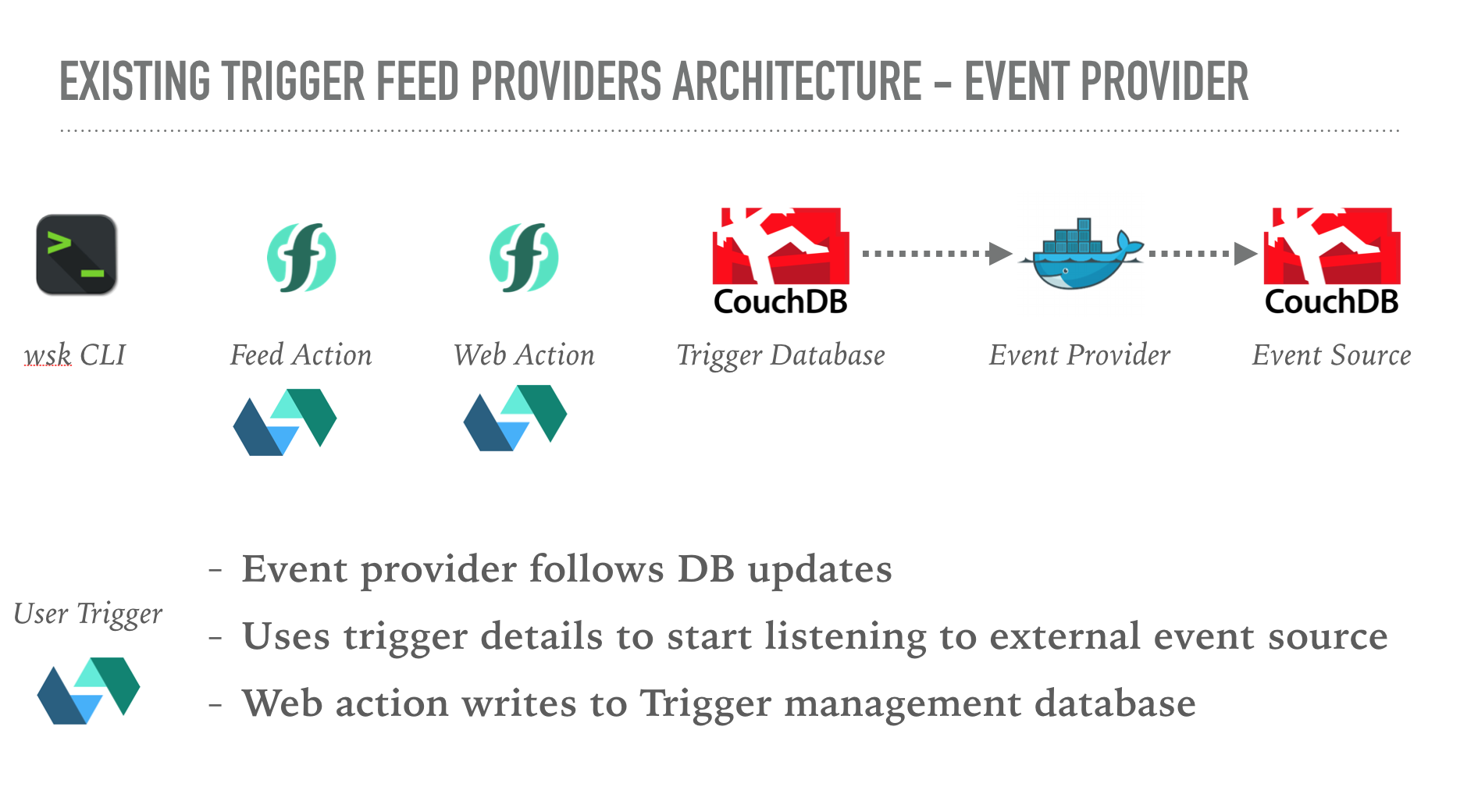
The CouchDB feed provider is a good example of how feed providers can be implemented.
This action just proxies the incoming requests to a separate web action. The web action implements the logic to handle the trigger lifecycle event. The web action uses a CouchDB database used to store registered triggers. Based upon the lifecycle event details, the web action updates the database document for that trigger.
The feed provider also runs a seperate Docker container, which handles listening to CouchDB change feeds from user-provided credentials. It uses the changes feed from the trigger management database, modified from the web action, to listen for triggers being added, removed, disabled or re-enabled.
When database change events occur, the container fires triggers on the platform with the event details.
building a new event provider?
Having understood how feed providers work (and how the existing providers were designed), I started to think about the new event source for an S3-compatible object store.
Realising ~90% of the code between providers was the same, I wondered if there was a different approach to creating new event providers, rather than cloning an existing provider and changing the small amount of code used to interact with the event sources.
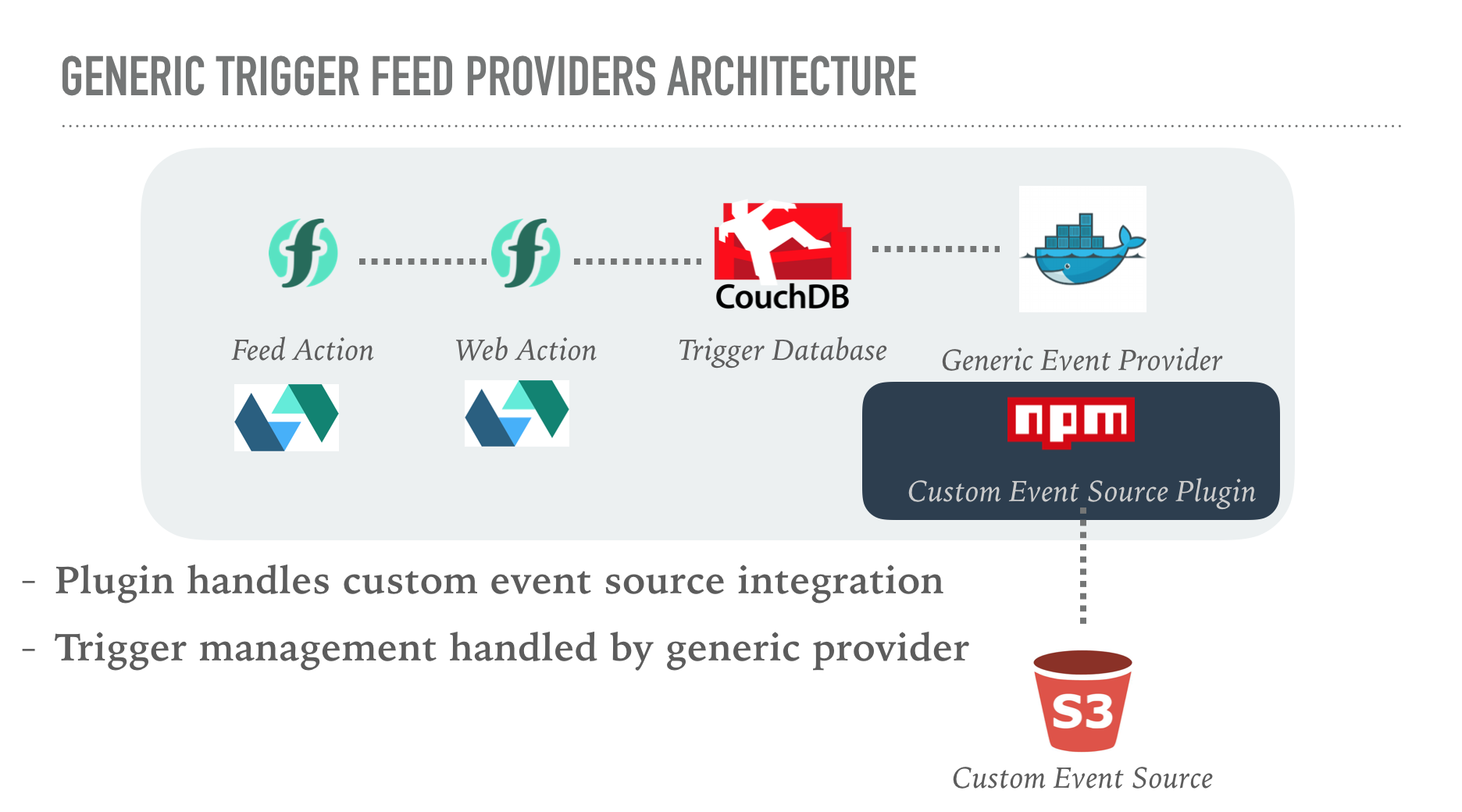
What about building a generic event provider which a pluggable event source?
This generic event provider would handle all the trigger management logic, which isn’t specific to individual event sources. The event source plugin would manage connecting to external event sources and then firing triggers as event occurred. Event source plugins would implement a standard interface and be registered dynamically during startup.
advantages
Using this approach would make it much easier to contribute and maintain new event sources.
Users would be able to create new event sources with a few lines of custom integration code, rather than replicating all the generic trigger lifecycle management code.
Maintaining a single repo for the generic event provider is easier than having the same code copied and pasted in multiple independent repositories.
I started hacking away at the existing CouchDB event provider to replace the event source integration with a generic plugin interface. Having completed this, I then wrote a new S3-compatible event source using the plugin model. After a couple of weeks I had something working….
generic event provider
The generic event provider is based on the exiting CouchDB feed provider source code. The project contains the stateful container code and feed package actions (public & web). It uses the same platform services (CouchDB and Redis) as the existing provider to maintain trigger details.
The event provider plugin is integrated through the EVENT_PROVIDER environment variable. The name should refer to a Node.js module from NPM with the following interface.
123456789101112
// initialise plugin instance (must be a JS constructor)module.exports=function(trigger_manager,logger){// register new trigger feedconstadd=async(trigger_id,trigger_params)=>{}// remove existing trigger feedconstremove=asynctrigger_id=>{}return{add,remove}}// valiate feed parametersmodule.exports.validate=asynctrigger_params=>{}
When a new trigger is added to the trigger feeds’ database, the details will be passed to the add method. Trigger parameters will be used to set up listening to the external event source. When external events occur, the trigger_manager can be use to automatically fire triggers.
When users delete triggers with feeds, the trigger will be removed from the database. This will lead to the remove method being called. Plugins should stop listening to messages for this event source.
firing trigger events
As event arrive from the external source, the plugin can use the trigger_manager instance, passed in through the constructor, to fire triggers with the identifier.
The trigger_manager parameter exposes two async functions:
fireTrigger(id, params) - fire trigger given by id passed into add method with event parameters.
disableTrigger(id, status_code, message) - disable trigger feed due to external event source issues.
Both functions handle the retry logic and error handling for those operations. These should be used by the event provider plugin to fire triggers when events arrive from external sources and then disable triggers due to external event source issues.
validating event source parameters
This static function on the plugin constructor is used to validate incoming trigger feed parameters for correctness, e.g. checking authentication credentials for an event source. It is passed the trigger parameters from the user.
S3 event feed provider
Using this new generic event provider, I was able to create an event source for an S3-compatible object store. Most importantly, this new event source was implemented using just ~300 lines of JavaScript! This is much smaller than the 7500 lines of code in the generic event provider.
The feed provider polls buckets on an interval using the ListObjectsAPI call. Results are cached in Redis to allow comparison between intervals. Comparing the differences in bucket file name and etags, allows file change events to be detected.
Users can call the feed provider with a bucket name, endpoint, API key and polling interval.
Pssst - if you are using IBM Cloud Functions - I actually have this deployed and running so you can try it out. Use the /james.thomas@uk.ibm.com_dev/s3-trigger-feed/changes feed action name. This package is only available in the London region.
next steps
Feedback on the call was overwhelming positive on my experiment. Based upon this, I’ve now open-sourced both the generic event provider and s3 event source plugin to allow the community to evaluate the project further.
I’d like to build a few more example event providers to validate the approach further before moving towards contributing this code back upstream.
If you want to try this generic event provider out with your own install of OpenWhisk, please see the documentation in the README for how to get started.
If you want to build new event sources, please see the instructions in the generic feed provider repository and take a look at the S3 plugin for an example to follow.
Imagine you have an OpenWhiskaction to send emails to users to verify their email addresses. User profiles, containing email addresses and verification statuses, are maintained in a CouchDB database.
Setting up a CouchDB trigger feed allows the email action to be invoked when the user profile changes. When user profiles have unverified email addresses, the action can send verification emails.
Whilst this works fine - it will result in a lot of unnecessary invocations. All modifications to user profiles, not just the email field, will result in the action being invoked. This will incur a cost despite the action having nothing to do.
How can we restrict document change events to just those we care about?
Filter functions are Javascript functions executed against (potential) change feed events. The function is invoked with each document update. The return value is evaluated as a boolean variable. If true, the document is published on the changes feed. Otherwise, the event is filtered from the changes feed.
example
Filter functions are created through design documents. Function source strings are stored as properties under the filters document attribute. Key names are used as filter identifiers.
Filter functions should have the following interface.
doc is the modified document object and req contains (optional) request parameters.
Let’s now explain how to create a filter function to restrict profile update events to just those with unverified email addresses…
Filtering Profile Updates
user profile documents
In this example, email addresses are stored in user profile documents under the email property. address contains the user’s email address and status records the verification status (unverified or verified).
When a new user is added, or an existing user changes their email address, the status attribute is set to unverified. This indicates a verification message needs to be sent to the email address.
The trigger only fires when a profile change contains an unverified email address. No more unnecessary invocations, which saves us money! 😎
caveats
“Why are users getting multiple verification emails?” 😡
If a user changes their profile information, whilst leaving their email address the same but before clicking the verification email, an additional email will be sent.
This is because the status field is still in the unverified state when the next document update occurs. Filter functions are stateless and can’t decide if this email address has already been seen.
Instead of leaving the status field as unverified, the email action should change the state to another value, e.g. pending, to indicate the verification email has been sent.
Any further document updates, whilst waiting for the verification response, won’t pass the filter and users won’t receive multiple emails. 👍
Conclusion
CouchDB filters are an easy way to subscribe to a subset of events from the changes feed. Combining CouchDB trigger feeds with filters allows actions to ignore irrelevant document updates. Multiple trigger feeds can be set up from a single database using filter functions.
As well as saving unnecessary invocations (and therefore money), this can simplify data models. A single database can be used to store all documents, rather than having to split different types into multiple databases, whilst still supporting changes feeds per document type.
Java actions are deployed from JAR files containing application class files. External libraries can be used by bundling those dependencies into a fat JAR file. The JAR file must be less than the maximum action size of 48MB.
So, what if the application uses lots of external libraries and the JAR file is larger than 48MB? 🤔
Apache OpenWhisk’s support for custom Docker runtimes provides a workaround. In a previous blog post, we showed how this feature could be used with Python applications which rely on lots of external libraries.
Using the same approach with Java, a custom Java runtime can be created with additional libraries pre-installed. Those libraries do not need to be included in the application jar, which will just contain private class files. This should hopefully reduce the JAR file to under the action size limit.
Let’s walk through an example to show how this works….
This example Java action capitalises sentences from the input event. It uses the Apache Commons Text library to handle capitialisation of input strings. This external library will be installed in the runtime, rather than bundled in the application JAR file.
Note: com.google.code.gson:gson:2.6.2 is used by the runtime to handle JSON encoding/decoding. Do not remove this dependency.
Execute the following command to build the custom Docker image.
1
./gradlew core:java8:distDocker
Push Image To Docker Hub
If the build process succeeds, a local Docker image named java8action should be available. This needs to be pushed to Docker Hub to allow Apache OpenWhisk to use it.
--main is the class file name containing the action handler in the JAR file. --docker is the Docker image name for the custom runtime.
Test it out!
Execute the capitialize action with input text to returned capitalised sentences.
1
wsk action invoke capitialize -b -r -p message "this is a sentence"
If this works, the following JSON should be printed to the console.
123
{"capitalized":"This Is A Sentence"}
The external library has been used in the application without including it in the application JAR file! 💯💯💯
Conclusion
Apache OpenWhisk supports running Java applications using fat JARs, which bundle application source code and external dependencies. JAR files cannot be more than 48MB, which can be challenging when applications uses lots of external libraries.
If application source files and external libraries result in JAR files larger than this limit, Apache OpenWhisk’s support for custom Docker runtimes provide a solution for running large Java applications on the platform.
By building a custom Java runtime, extra libraries can be pre-installed in the runtime. These dependencies do not need to be included in the application JAR file, which reduces the file size to under the action size limit. 👍
Terraform is an open-source ”infrastructure-as-code” tool. It allows cloud resources to be defined using a declarative configuration file. The Terraform CLI then uses this file to automatically provision and maintain cloud infrastructure needed by your application. This allows the creation of reproducible environments in the cloud across your application life cycle.
IBM Cloud created an official provider plugin for Terraform. This allows IBM Cloud services to be declared in Terraform configuration files. This is a much better approach than using the CLI or IBM Cloud UI to create application services manually.
The following steps needed to set up Terraform with IBM Cloud will be explained.
Install Terraform CLI tools and IBM Cloud Provider Plugin.
Create API keys for platform access.
Terraform configuration for IBM Cloud services.
Terraform CLI commands to provision IBM Cloud services.
IBM Cloud’s Terraform provider plugin needs authentication credentials to interact with the platform. This is best handled by creating an API key and exporting as an environment variable. API keys can be created from the IBM Cloud CLI or the web site.
Under the ”API keys” table, click the ”Create an IBM Cloud API Key” button.
Give the key a name and (optional) description.
Make a note of the API key value returned. API keys cannot be retrieved after creation.
exporting as an environment variable
Expose the API key as an environment variable to provide credentials to Terraform.
1
export BM_API_KEY=API_KEY_VALUE
Terraform configuration
We can now start to write configuration files to describe IBM Cloud services we want to provision. Terraform configuration files are human-readable text files, ending with the .tf extension, which contain HashiCorp Configuration Language (HCL) syntax.
IBM Cloud platform services come in two flavours: IAM managed resource instances and older Cloud Foundry-based service instances. This is due to the history of IBM Cloud starting as Bluemix, a Cloud Foundry-based cloud platform. Both platform services types can be provisioned using Terraform.
Most IBM Cloud platform services are available today as ”resource instances”.
create new configuration file
Create a new infra.tf file which contains the following syntax.
Refreshing Terraform state in-memory prior to plan...
The refreshed state will be used to calculate this plan, but will not be
persisted to local or remote state storage.
------------------------------------------------------------------------
An execution plan has been generated and is shown below.
Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
+ ibm_resource_instance.cloudant
id: <computed>
location: "us-south"
name: "my-cloudant-db"
plan: "lite"
service: "cloudantnosqldb"
status: <computed>
+ ibm_resource_key.cloudant_key
id: <computed>
credentials.%: <computed>
name: "my-db-key"
parameters.%: <computed>
resource_instance_id: "${ibm_resource_instance.cloudant.id}"
role: "Manager"
status: <computed>
Plan: 2 to add, 0 to change, 0 to destroy.
------------------------------------------------------------------------
API keys from the cloudant_credentials output section can be used applications to interact with the provisioned database! 👏👏👏
Conclusion
Provisioning cloud services using Terraform is a great way to manage application resources on IBM Cloud.
Applications resources are defined in a declarative configuration file, following the “infrastructure-as-code” approach to managing cloud environments. This configuration is maintained in the application’s source code repository to enable reproducible environments.
IBM Cloud provides an official provider plugin for Terraform. This allows IBM Cloud services to be defined through custom configuration primitives. Developers can then use the Terraform CLI to provision new resources and extract service keys needed to access those services. 💯💯💯
But what happens when you need execute multiple asynchronous tasks (implemented as separate functions) from an incoming event, like an API request? 🤔
Functions Calling Functions?
Functions can invoke other functions directly, using asynchronous calls through the client SDK. This works at the cost of introducing tighter coupling between functions, which is generally avoided in software engineering! Disadvantages of this approach include…
Functions which call other functions can be more difficult to test. Test cases needs to mock out the client SDK to remove side-effects during unit or integration tests.
It can lead to repetitive code if you want to fire multiple tasks with the same event. Each invocation needs to manually handle error conditions and re-tries on network or other issues, which complicates the business logic.
Modifying the functions being invoked cannot be changed dynamically. The function doing the invoking has to be re-deployed with updated code.
Some people have even labelled ”functions calling functions” an anti-pattern in serverless development! 😱
Most common Serverless mistake?
Functions calling other functions
Why do people make this mistake?
Because people assume they should build functions like microservices and then use them in a similar way.
Causes no end of problems
— Serverless / Green Data Advocate (@PaulDJohnston) January 15, 2019
Hmmm… so what should we do?
Apache OpenWhisk has an awesome feature to help with this problem, triggers and rules! 👏
OpenWhisk Triggers & Rules
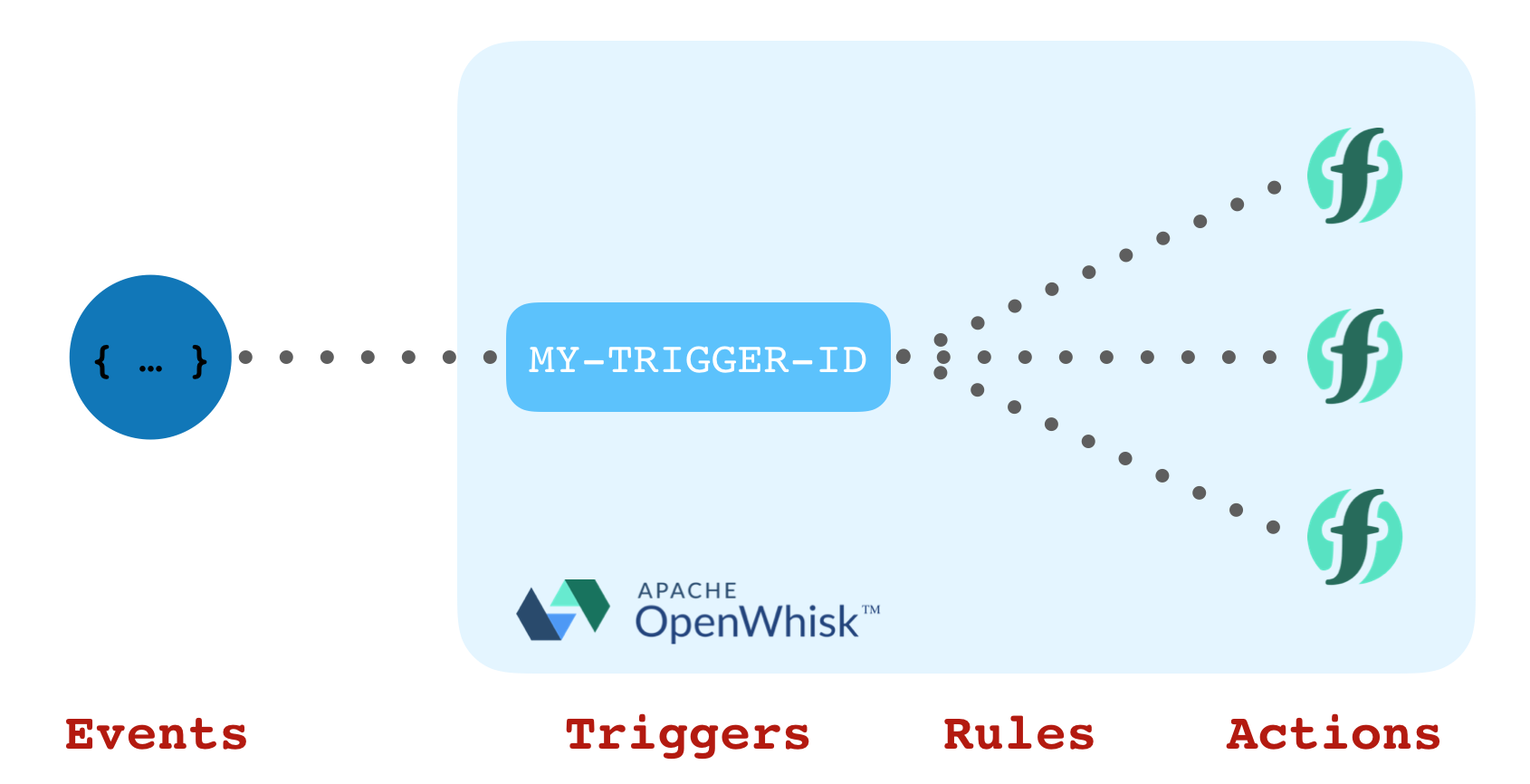
Triggers and Rules in OpenWhisk are similar to the Observer pattern from software engineering.
Users can fire “events” in OpenWhisk by invoking a named trigger with parameters. Rules are used to “subscribe” actions to all events for a given trigger name. Actions are invoked with event parameters when a trigger is fired. Multiple rules can be configured to support multiple “listeners” to the same trigger events. Event senders are decoupled from event receivers.
Developers using OpenWhisk are most familiar with triggers when used with feed providers. This is used to subscribe actions to external event sources. The feed provider is responsible for listening to the event source and automatically firing trigger events with event details.
But triggers can be fired manually from actions to provide custom event streams! 🙌
12345678
constopenwhisk=require('openwhisk')constparams={msg:'event parameters'}// replace code like this...constresult=awaitow.actions.invoke({name:"some-action",params})// ...with thisconstresult=awaitow.triggers.invoke({name:"some-trigger",params})
This allows applications to move towards an event-driven architecture and promotes loose-coupling between functions with all the associated benefits for testing, deployment and scalability. 👌
creating triggers
Triggers are managed through the platform API. They can be created, deleted, retrieved and fired using HTTP requests. Users normally interact with triggers through the CLI or platform SDKs.
Triggers can be created using the following CLI command.
1
wsktriggercreate<TRIGGER_NAME>
default parameters
Triggers support default parameters like actions. Default parameters are stored in the platform and included in all trigger events. If the event object includes parameters with the same key, default parameter values are ignored.
Rules bind triggers to actions. When triggers are fired, all actions connected via rules are invoked with the trigger event. Multiple rules can refer to the same trigger supporting multiple listeners to the same event.
Rules can also be created using the following CLI command.
1
wskrulecreateRULE_NAMETRIGGER_NAMEACTION_NAME
Tools like The Serverless Framework and wskdeploy allow users to configure triggers and rules declaratively through YAML configuration files.
Activation records are created for trigger events. These activation records contain event parameters, rules fired, activations ids and invocation status for each action invoked. This is useful for debugging trigger events when issues are occurring.
Activation records are only generated when triggers have enabled rules with valid actions attached
Example - WC Goal Bot
This is great in theory but what about in practice?
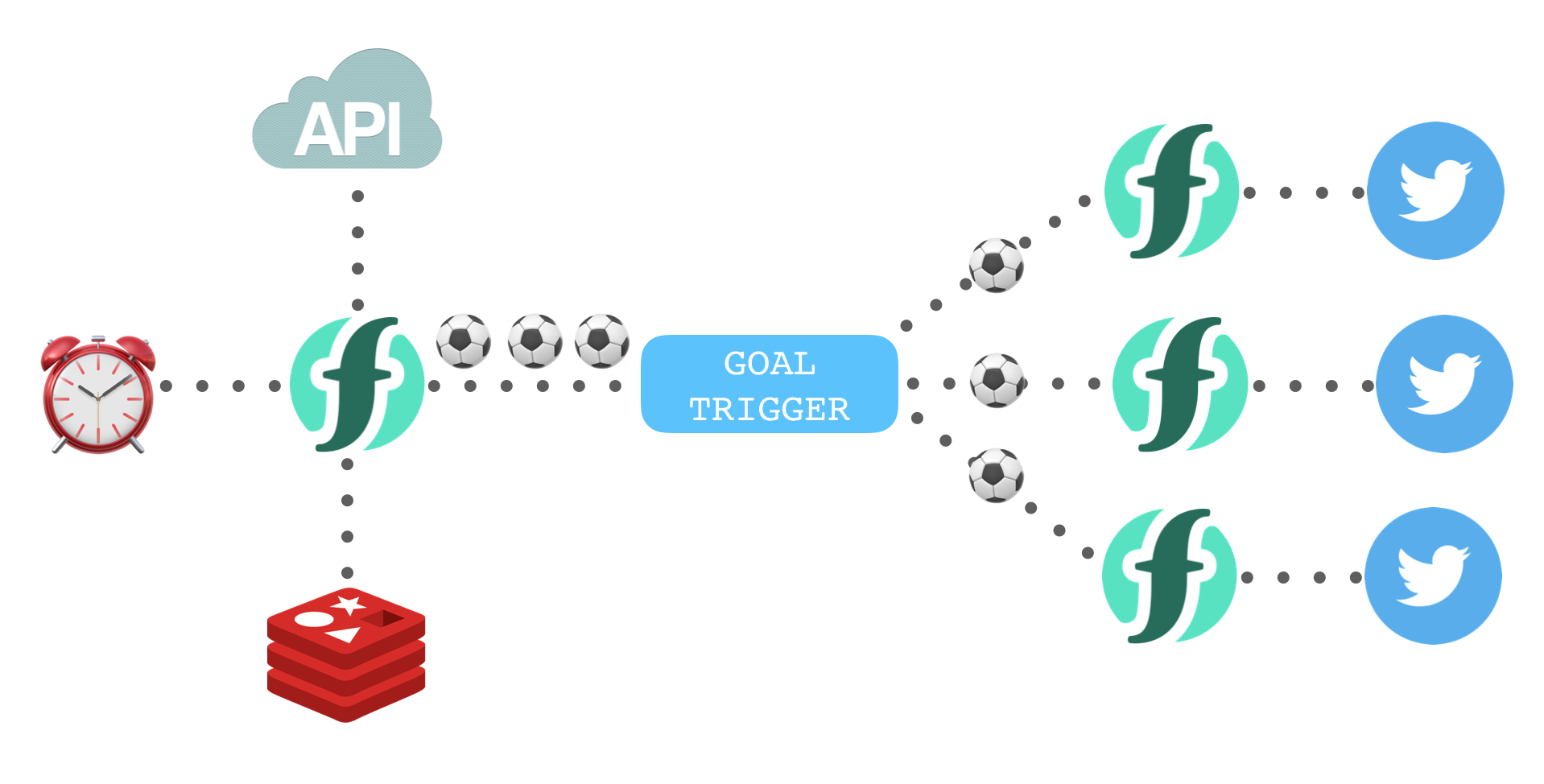
Goal Bot was a small serverless application I built in 2018 for the World Cup. It was a Twitter bot which tweeted out all goals scored in real-time. The application used the “actions connected via triggers events” architecture pattern. This made development and testing easier and faster.
⚽️ GOAL ⚽️ 👨 Harry MAGUIRE (🏴 ) @ 30'. 👨 🏟 Sweden 🇸🇪 (0) v England 🏴 (1) 🏟#WorldCup
This function has two functions goals and twitter.
goals was responsible for detecting new goals scored using an external API. When invoked, it would retrieve all goals currently scored in the World Cup. Comparing the API response to a previous cached version calculated new goals scored. This function was connected to the alarm event source to run once a minute.
twitter was responsible for sending tweets from the @WC_Goals account. Twitter’s API was used to create goal tweets constructed from the event parameters.
Goal events detected in the goals function need to be used to invoke the twitter function.
Rather than the goals function invoke the twitter function directly, a trigger event (goal) was fired. The twitter function was bound to the goal trigger using a custom rule.
De-coupling the two tasks in my application (checking for new goals and creating tweets) using triggers and rules had the following benefits…
The goals function could be invoked in testing without tweets being sent. By disabling the rule binding the twitter function to the trigger, the goals function can fire events without causing side-effects.
Compared to having a “mono-function” combining both tasks, splitting tasks into functions means the twitter function can be tested with manual events, rather than having to manipulate the database and stub API responses to generate the correct test data.
It would also be easy to extend this architecture with additional notification services, like slack bots. New notification services could be attached to the same trigger source with an additional rule. This would not require any changes to the goals or twitter functions.
Triggers versus Queues
Another common solution to de-coupling functions in serverless architectures is using message queues.
Functions push events in external queues, rather than invoking triggers directly. Event sources are responsible for firing the registered functions with new messages. Apache OpenWhisk supports Kafka as an event source which could be used with this approach.
How does firing triggers directly compare to pushing events into an external queue (or other event source)?
Both queues and triggers can be used to achieve the same goal (”connect functions via events”) but have different semantics. It is important to understand the benefits of both to choose the most appropriate architecture for your application.
benefits of using triggers against queues
Triggers are built into the Apache OpenWhisk platform. There is no configuration needed to use them. External event sources like queues need to be provisioned and managed as additional cloud services.
Trigger invocations are free in IBM Cloud Functions. IBM Cloud Functions charges only for execution time and memory used in functions. Queues will incur additional usage costs based on the service’s pricing plan.
disadvantages of using triggers against queues
Triggers are not queues. Triggers are not queues. Triggers are not queues. 💯
If a trigger is fired and no actions are connected, the event is lost. Trigger events are not persisted until listeners are attached. If you need event persistence, message priorities, disaster recovery and other advanced features provided by message queues, use a message queue!
Triggers are subject to rate limiting in Apache OpenWhisk. In IBM Cloud Functions, this defaults to 1000 concurrent invocations and 5000 total invocations per namespace per minute. These limits can be raised through a support ticket but there are practical limits to the maximum rates allowed. Queues have support for much higher throughput rates.
External event providers are also responsible for handling the retries when triggers have been rate-limited due to excess events. Invoking triggers manually relies on the invoking function to handle this. Emulating retry behaviour from an event provider is impractical due to costs and limits on function duration.
Other hints and tips
Want to invoke an action which fires triggers without setting off listeners?
Rules can be dynamically disabled without having to remove them. This can be used during integration testing or debugging issues in production.
12
wskruledisableRULE_NAMEwskruleenableRULE_NAME
Want to verify triggers are fired with correct events without mocking client libraries?
Trigger events are not logged unless there is at least one enabled rule. Create a new rule which binds the /whisk.system/utils/echo action to the trigger. This built-in function just returns input parameters as the function response. This means the activation records with trigger events will now be available.
conclusion
Building event-driven serverless applications from loosely-coupled functions has numerous benefits including development speed, improved testability, deployment velocity, lower costs and more.
Decomposing “monolithic” apps into independent serverless functions often needs event handling functions to trigger off multiple backend operations, implemented in separate serverless functions. Developers unfamiliar with serverless often resort to direct function invocations.
Whilst this works, it introduces tight coupling between those functions, which is normally avoided in software engineering. This approach has even been highlighted as a “serverless” anti-pattern.
Apache OpenWhisk has an awesome feature to help with this problems, triggers and rules!
Triggers provide a lightweight event firing mechanism in the platform. Rules bind actions to triggers to automate invoking actions when events are fired. Applications can fire trigger events to invoke other operations, rather than using direct invocations. This keeps the event sender and receivers de-coupled from each other. 👏
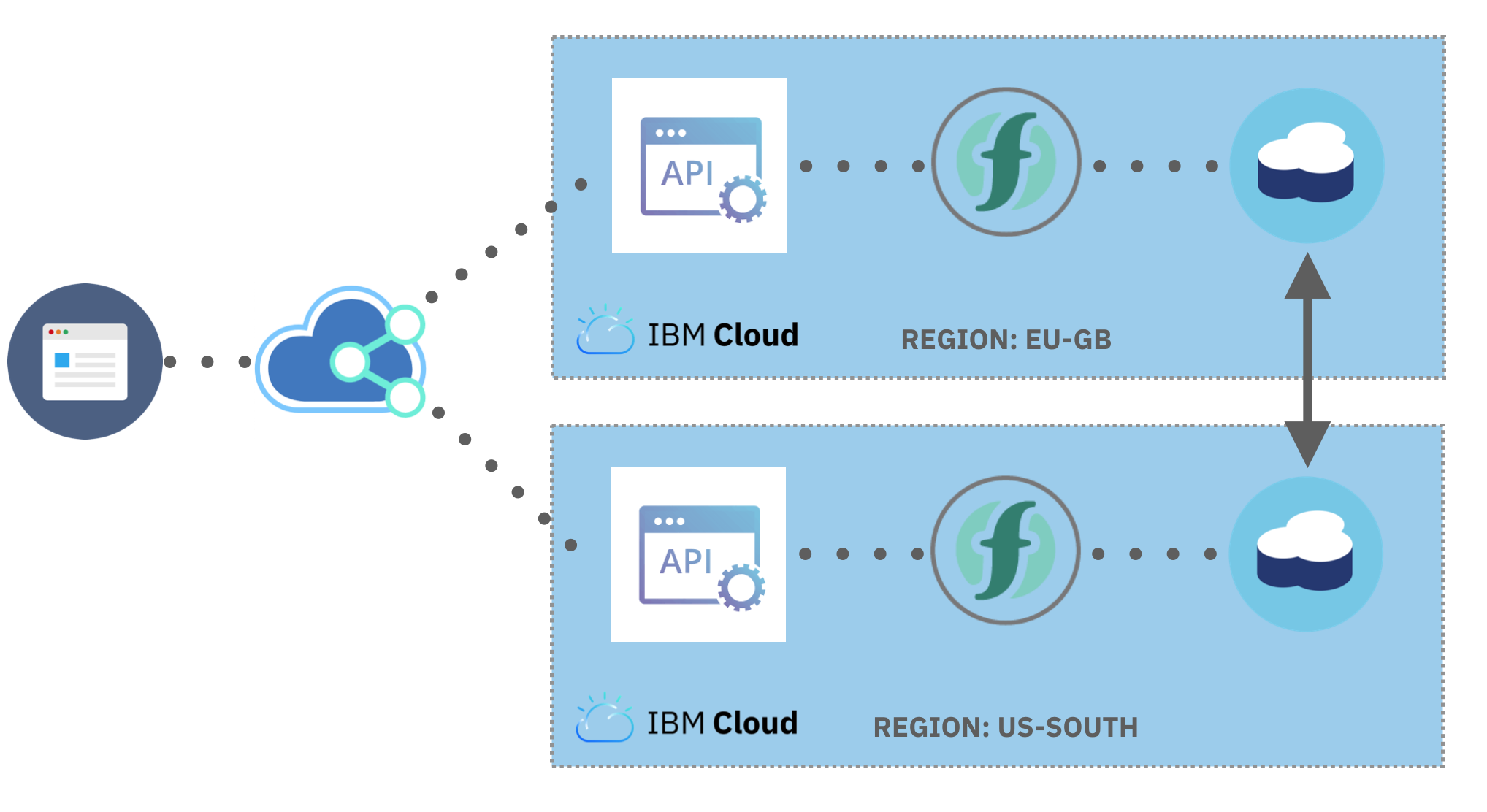
Existing tutorials showed how to deploy the same serverless application on IBM Cloud in different regions. Using the Global Load Balancer from IBM Cloud Internet Services, traffic is distributed across multiple applications from the same hostname. The Global Load Balancer automatically detects outages in the regional applications and redirects traffics as necessary.
But what if all instances rely on the same database service and that has issues? 😱🔥
In addition to running multiple instances of the application, independent databases in different regions are also necessary for a highly available serverless application. Maintaining consistent application state across regions needs all database changes to be automatically synchronised between instances. 🤔
Once this is enabled, database changes will automatically be synchronised in real-time between all database instances. Serverless applications can use their regional database instance and be confident application state will be consistent globally (for some definition of consistent…). 💯
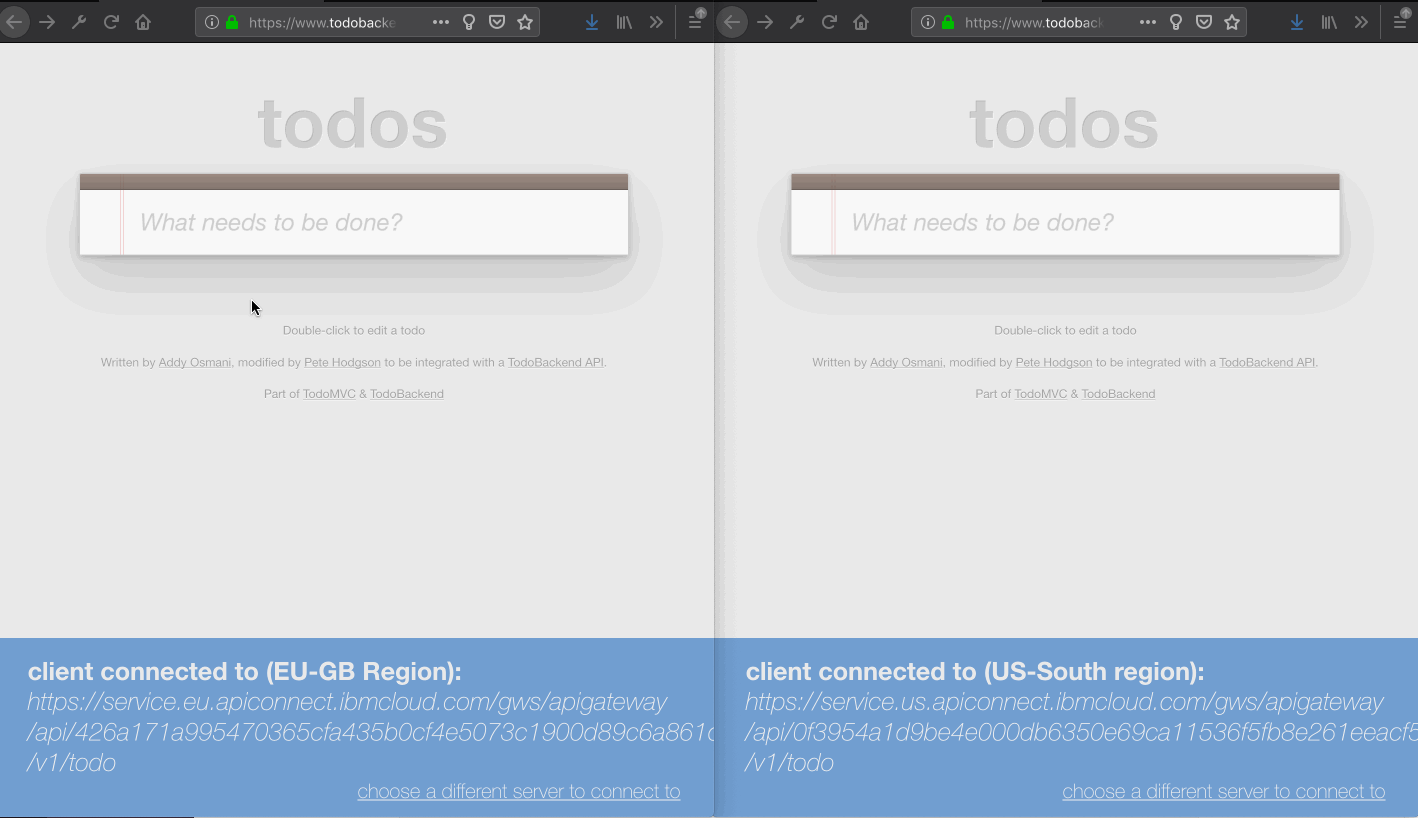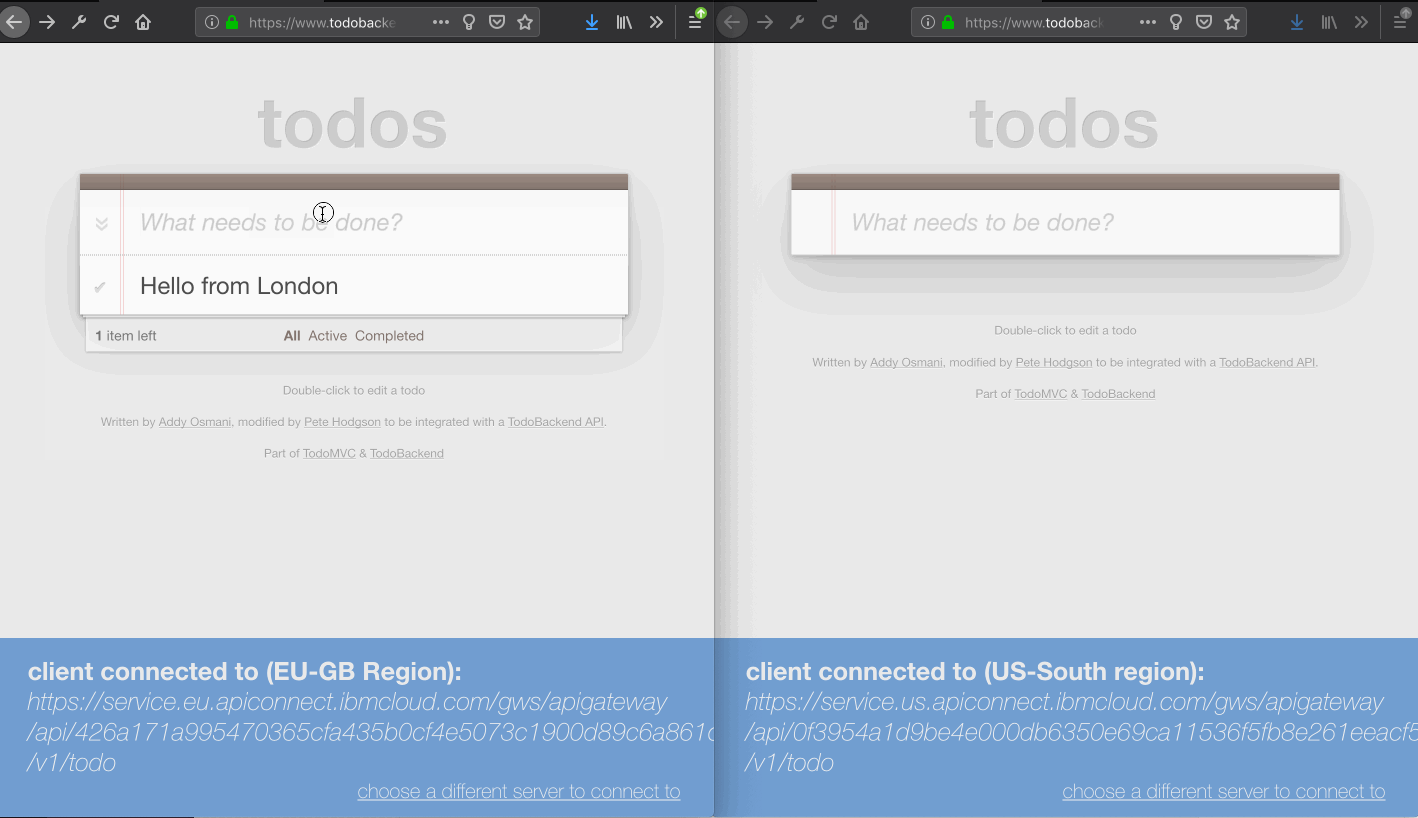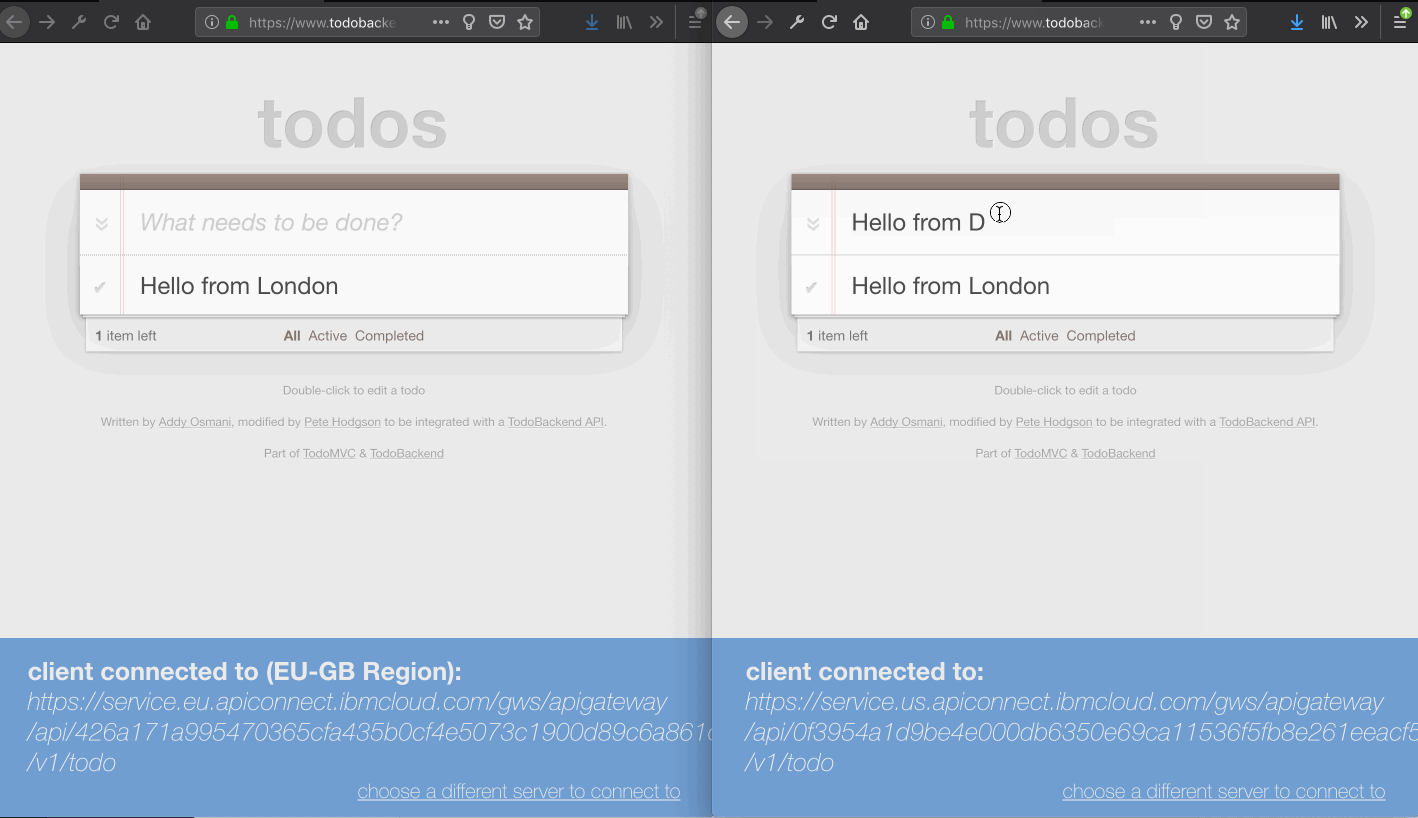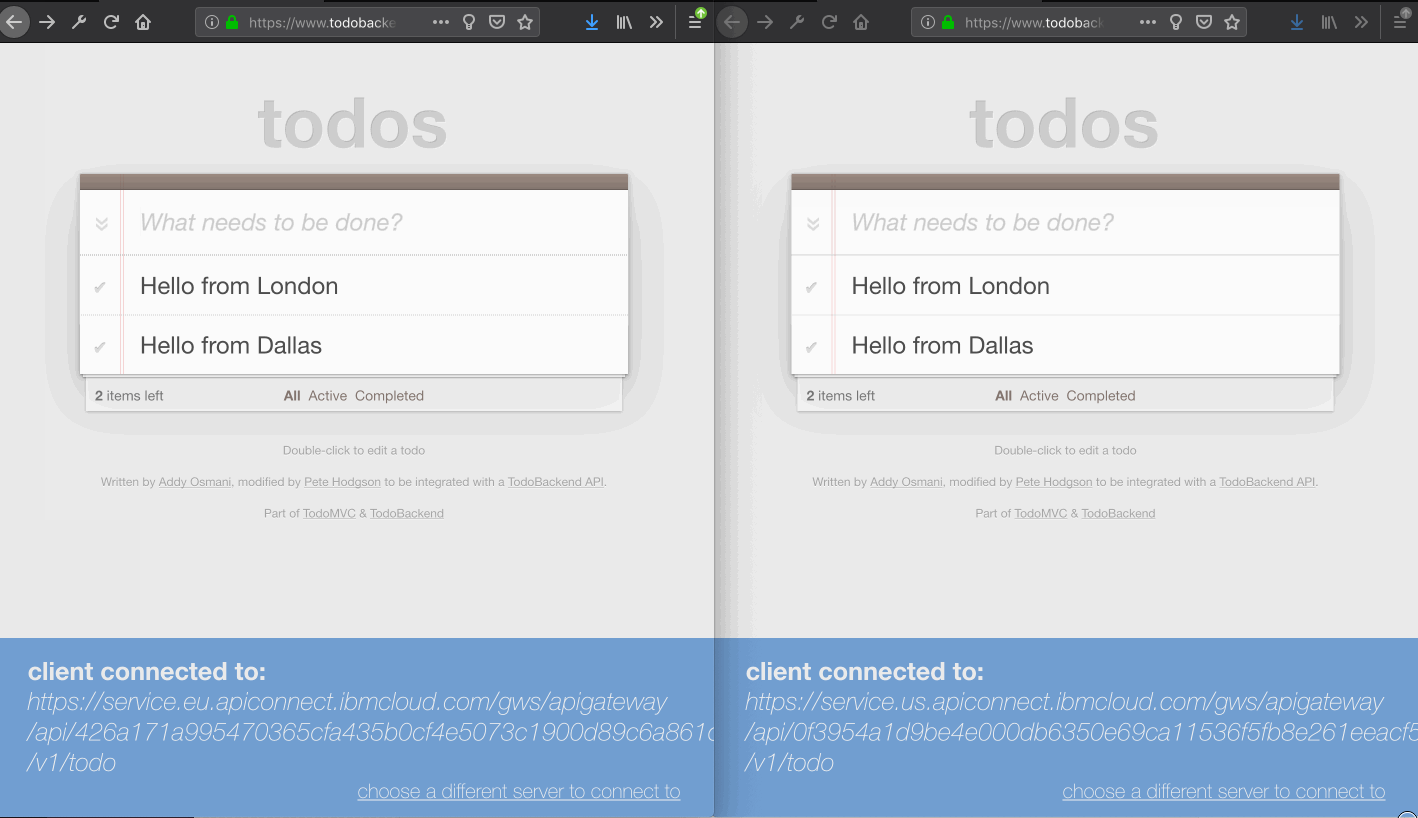
The application will be deployed to two different IBM Cloud regions (London and Dallas). Separate database instances will be provisioned in each region. Applications will use their regional database instance but share global state via replication.
deploy serverless app to multiple regions
This Github repo has an automatic deployment script to deploy the serverless application (using wskdeploy) and application services (using terraform).
Install the prerequisites listed here before proceeding with these instructions.
The PROVISION_INFRASTRUCTURE parameter makes the deployment script automatically provision all application resources using Terraform.
Secured API endpoints are not required for this demonstration. Setting the API_USE_APPID parameter to false disables authentication on the endpoints and provisioning the AppID service.
deploy to london
Set the IBMCLOUD_REGION to eu-gb in the local.env file.
Run the following command to deploy the application and provision all application resources.
1
./deploy.sh --install
If the deployment have succeed, the following message should be printed to the console.
12345
2019-01-08 10:51:51 All done.
ok: APIs
Action Verb API Name URL
/<ORG>_<SPACE>/todo_package/todo/get_todo get todos https://<UK_APIGW_URL>/todo
...
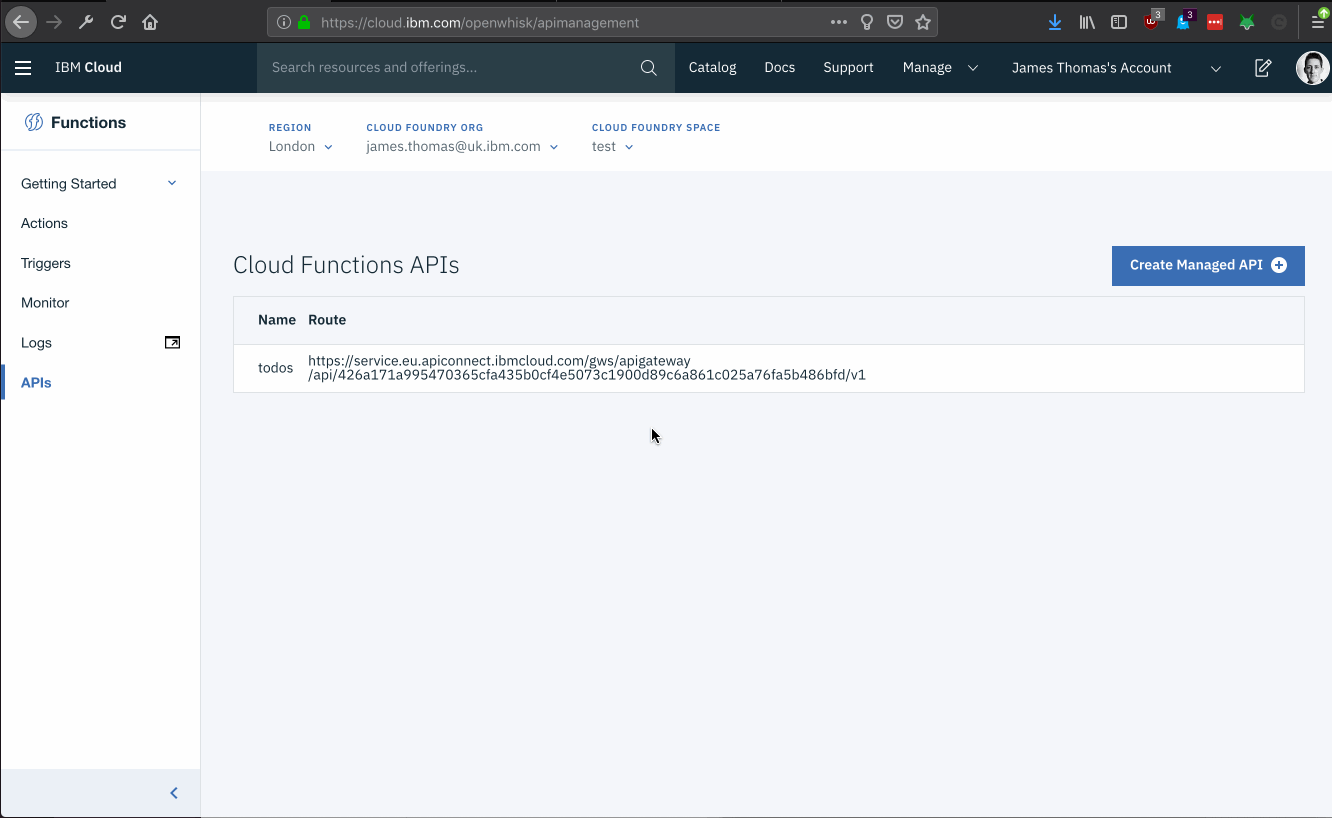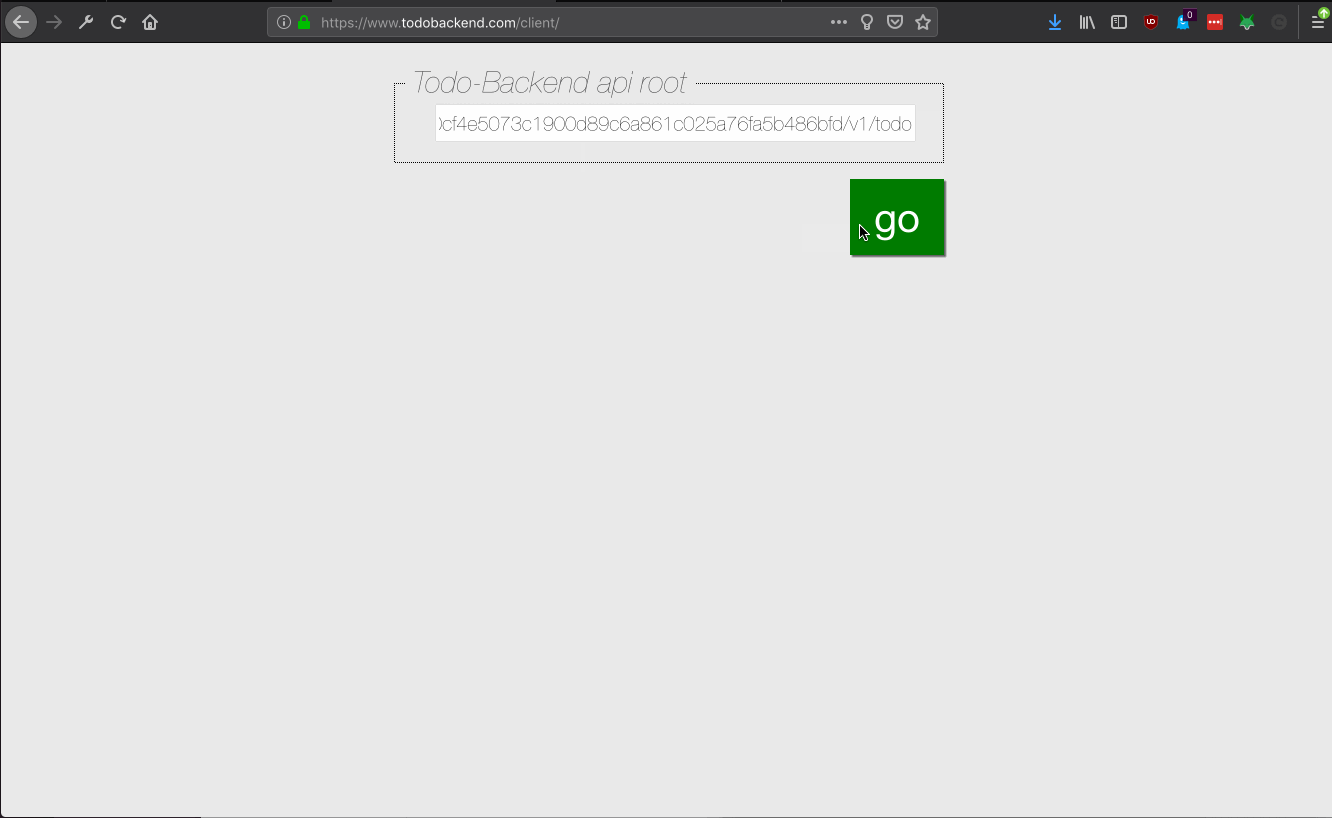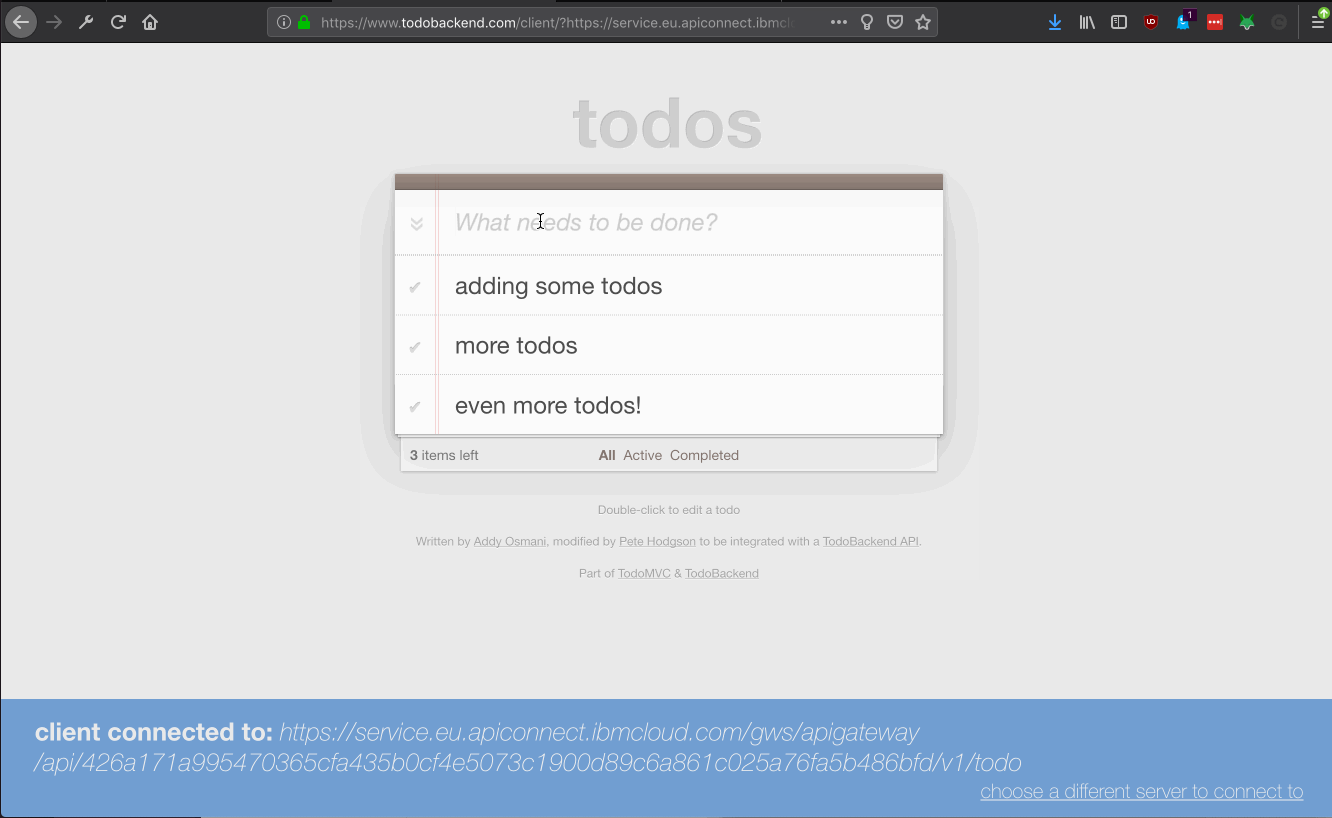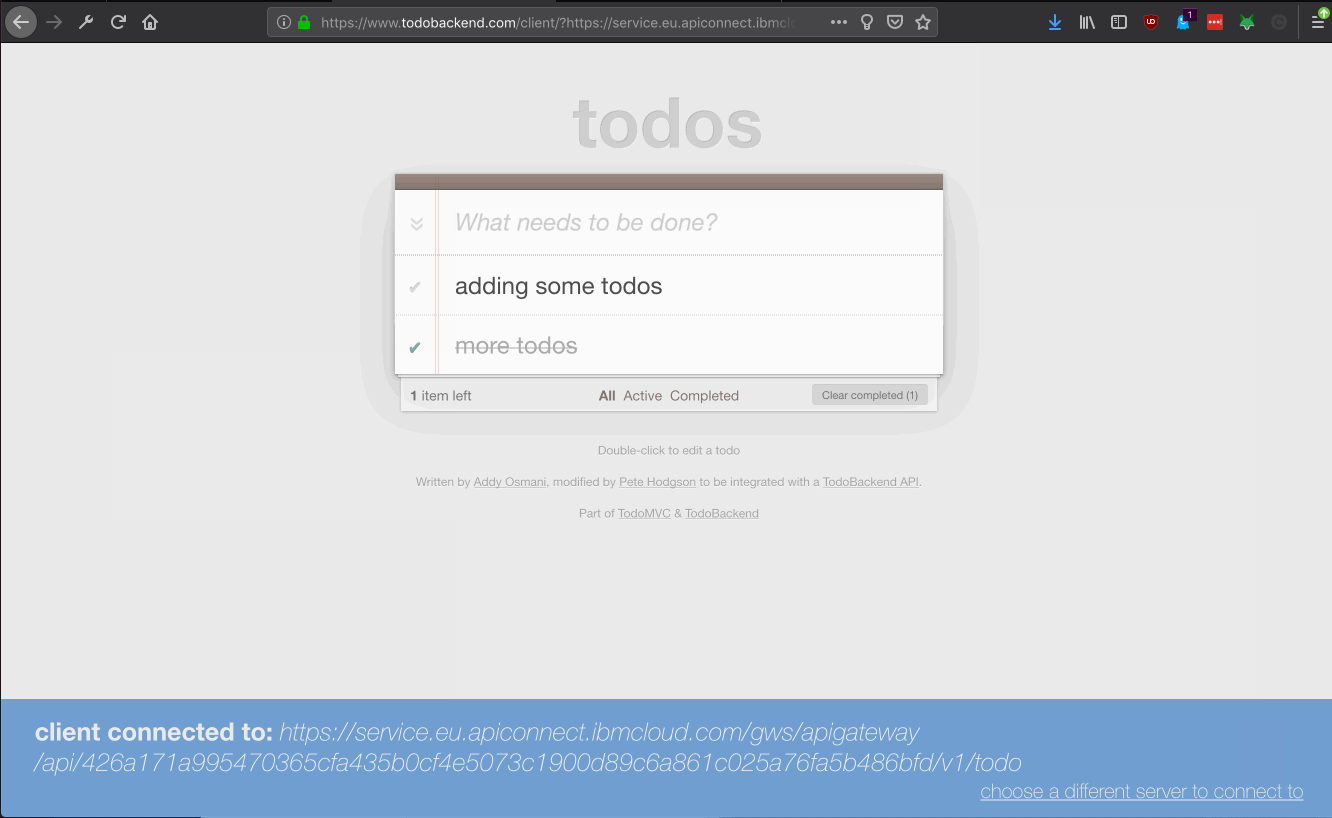
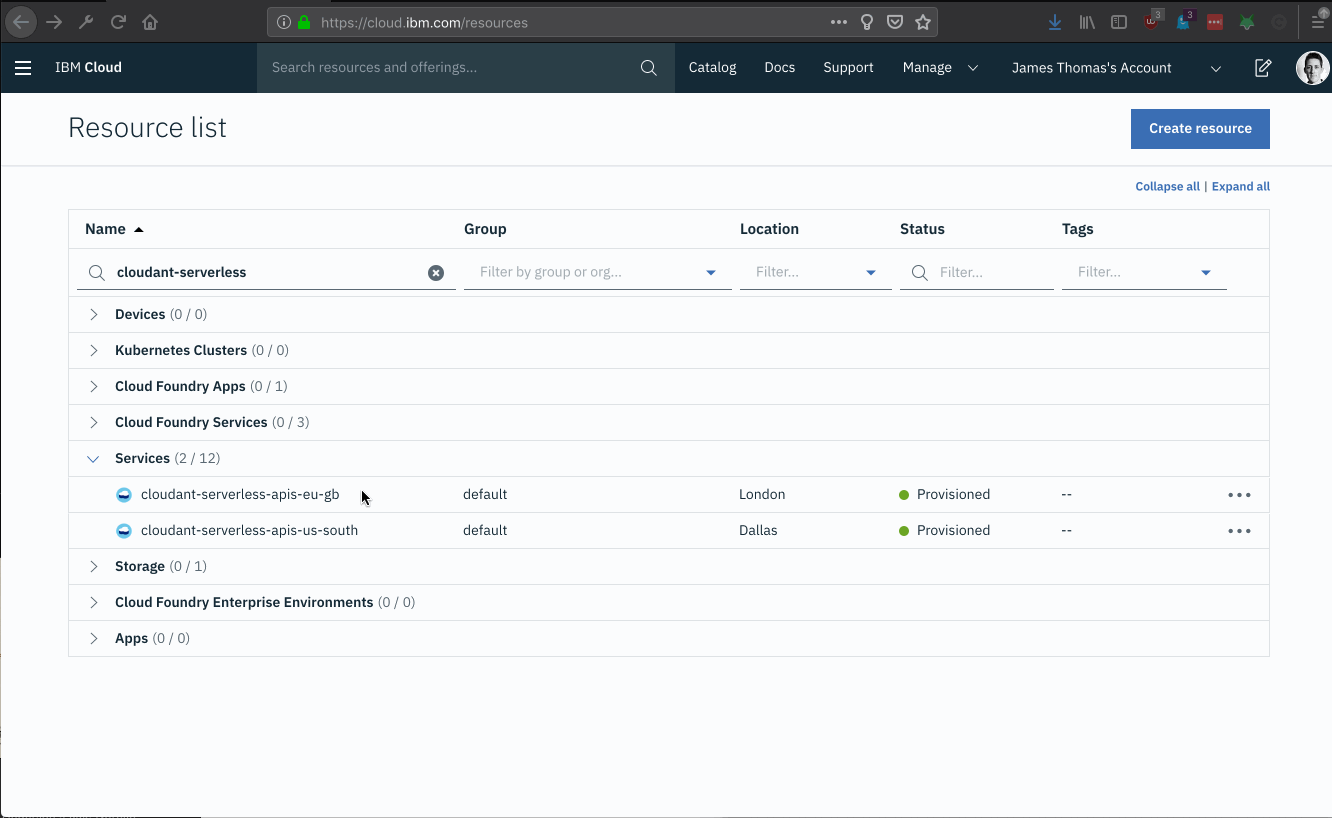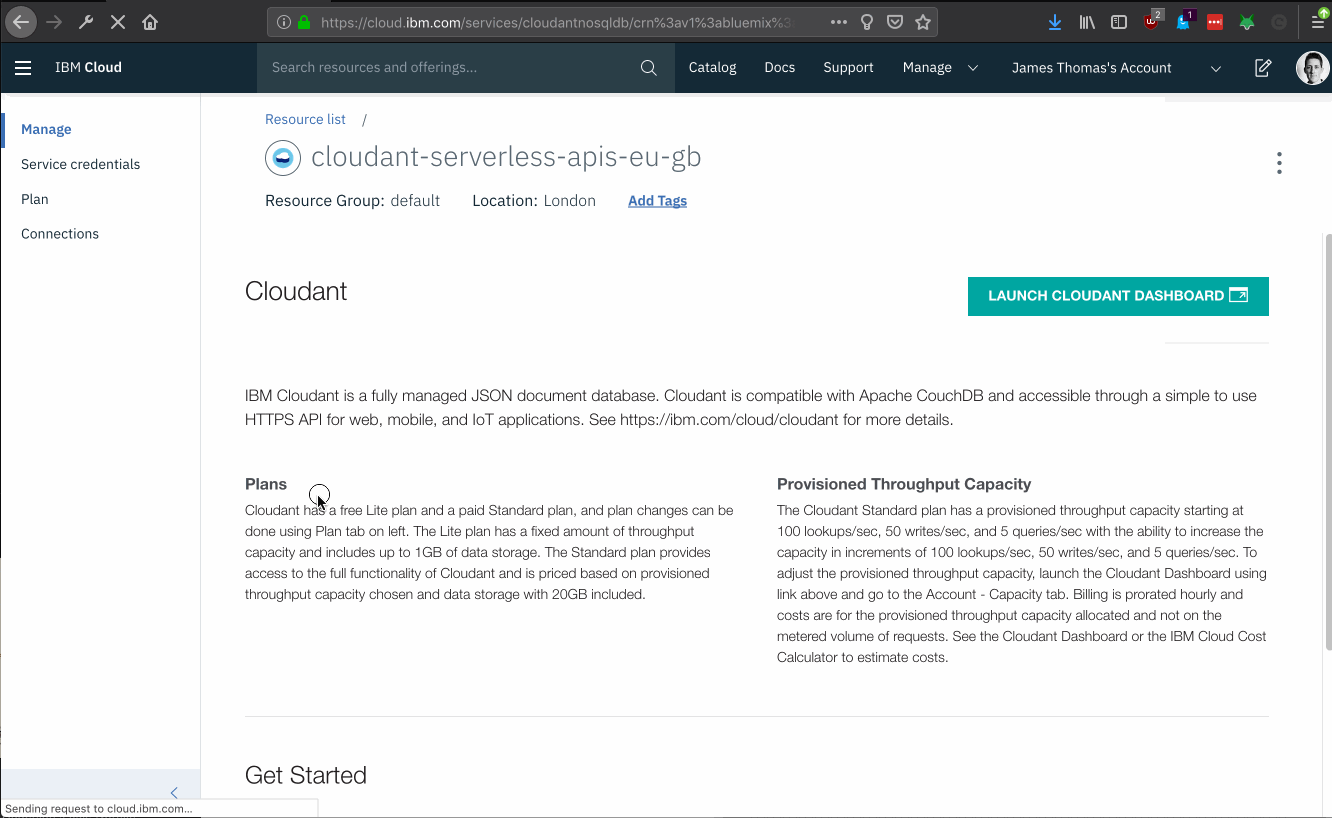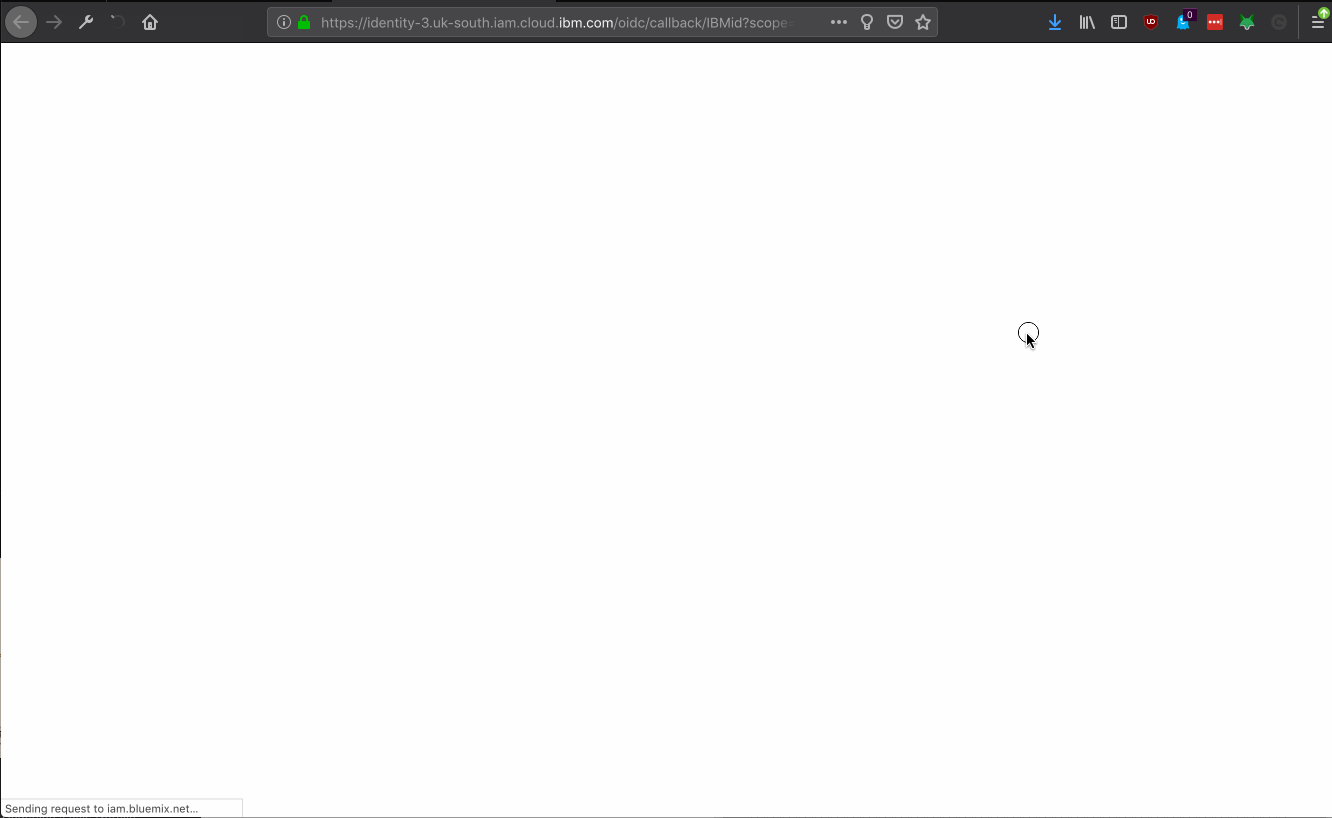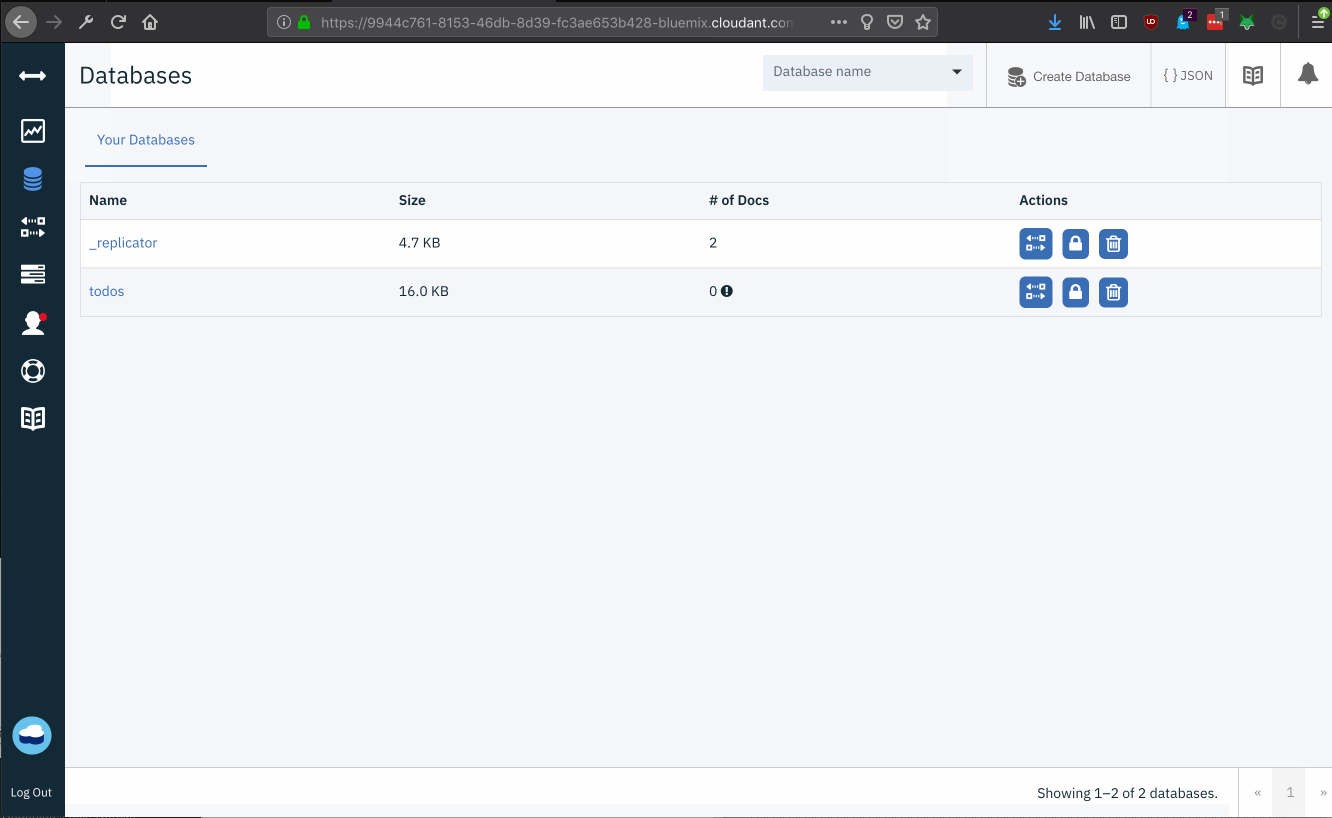
There are now multiple copies of the same serverless application in different regions. Each region has an independent instance of Cloudant provisioned.
Before configuring replication between the regional databases, API keys need to be created to allow remote access on both hosts. API keys need to be created per regional instance.
From the IBM Cloud Resource List, find the cloudant instances provisioned in London and Dallas.
Open the Cloudant Dashboard for each service instance.
Follow these instructions on both hosts to generate API keys for replication with the correct permissions.
Click the “Databases” icon to show all the databases on this instance.
Click the 🔒 icon in the “todos” database row in the table to open the permissions page.
Can’t find the “todos” database in the Cloudant dashboard? Make sure you interact with the TODO backend from the front-end application. This will automatically create the database if it doesn’t exist.
Click “Generate API Key” on the permissions page.
Make a note of the key identifier and password.
Set the _reader_, _writer and _replicator permissions for the newly created key.
set up cross-region replication
Replication jobs need to be configured on both database hosts. These can be created from the Cloudant dashboard. Repeat these instructions on both hosts.
Open the Cloudant Dashboard for each service instance.
Click the “Replication” icon from the panel menu.
Click the “New Replication” button.
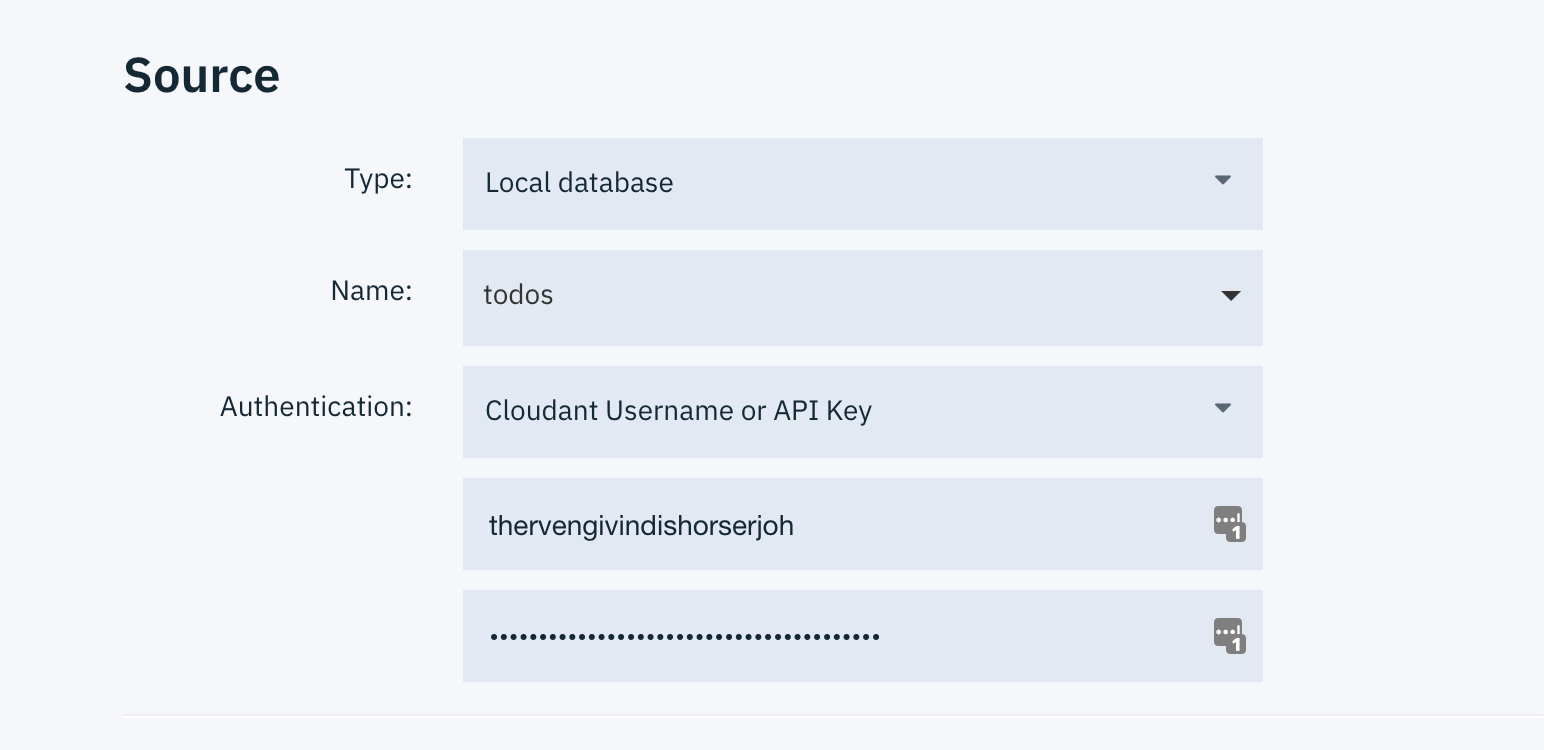
Set the following “Source” values in the “Job configuration” panel.
Type: “Local Database”
Name: “todos”
Authentication: “Cloudant username or API Key”
Fill in the API key and password for this local database host in the input fields.
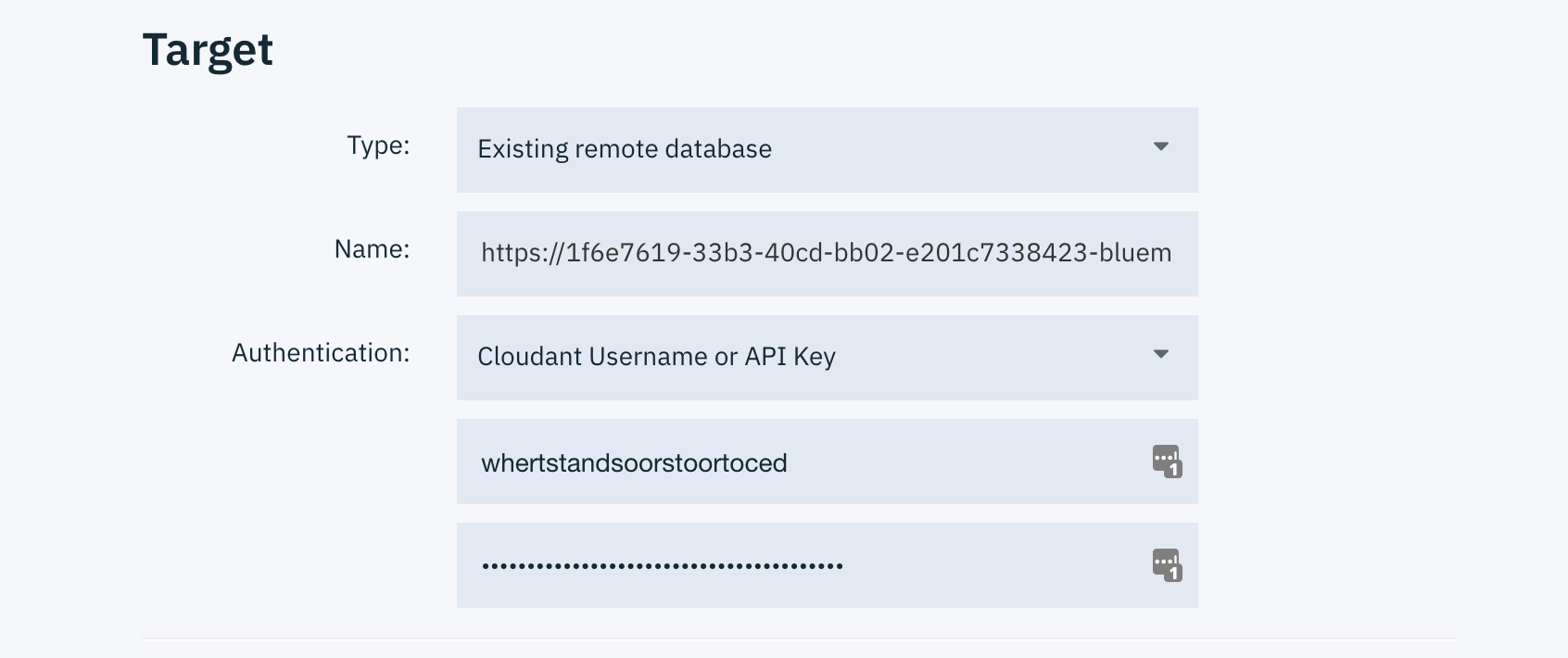
Set the following “Target” values in the “Job configuration” panel.
Type: “Existing Remote Database”
Name: “https:///todos”
Authentication: “Cloudant username or API Key”
Fill in the API key and password for the remote database host in the input fields.
Wondering what the REMOTE_CLOUDANT_HOST is? Use hostname from the Cloudant dashboard, e.g. XXXX-bluemix.cloudant.com
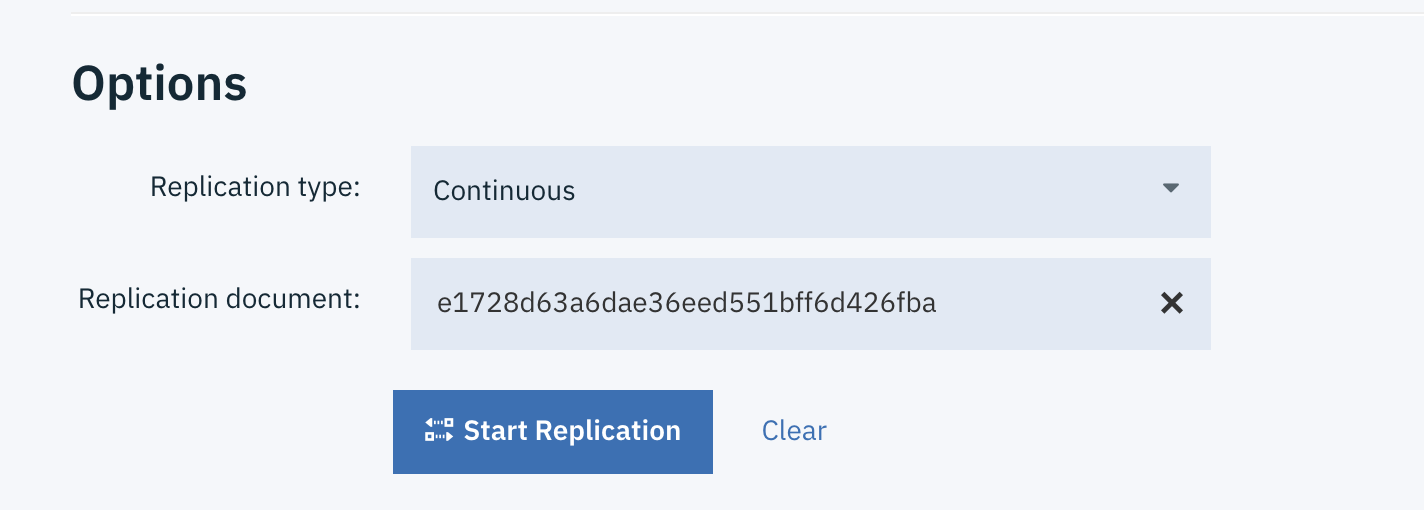
Set the following “Options” values in the “Job configuration” panel.
Replication type: “Continuous”
Click “Start Replication”
Verify the replication table shows the new replication task state as ”Running”. 👍
test it out!
Use the TODO front-end application with the APIGW URLs for each region simultaneously. Interactions with the todo list in one region should automatically propagate to the other region.
The “Active Tasks” panel on the Cloudant Dashboard shows the documents replicated between instances and pending changes. If there are errors synchronising changes to the replication target, the host uses exponential backoff to re-try the replication tasks.
Conflicts between document changes are handled using CouchDB’s conflict mechanism. Applications are responsible for detecting and resolving document conflicts in the front-end.
conclusion
Running the same serverless application in multiple regions, using the GLB to proxy traffic, allows applications to manage regional outages. But what if all the application instances rely on the same database service? The “single point of failure” has shifted from the application runtime to the database host. 👎
Provisioning independent databases in each application regions is one solution. Applications use their regional database instance and are protected from issues in other regions. This strategy relies on database changes being synchronised between instances to keep the application state consistent. 👍
IBM Cloudant has a built-in replication service to synchronised changes between source and host databases. Setting up bi-directional replication tasks between all instances enables a “multi-master” replication strategy. This allows applications to access any database instance and have the same state available globally. 🕺🕺🕺
In this tutorial, I’m going to show you how to use a custom domain for serverless functions exposed as APIs on IBM Cloud. APIs endpoints use a random sub-domain on IBM Cloud by default. Importing your own domains means endpoints can be accessible through custom URLs.
Registering a custom domain with IBM Cloud needs you to complete the following steps…
This tutorial assumes you already have actions on IBM Cloud Functions exposed as HTTP APIs using the built-in API service. If you haven’t done that yet, please see the documentation here before you proceed.
The instructions below set up a sub-domain (api.<YOUR_DOMAIN>) to access serverless functions.
Generating SSL/TLS Certificates with Let’s Encrypt
IBM Cloud APIs only supports HTTPS traffic with custom domains. Users needs to upload valid SSL/TLS certificates for those domains to IBM Cloud before being able to use them.
Let’s Encrypt is a Certificate Authority which provides free SSL/TLS certificates for domains. Let’s Encrypt is trusted by all root identify providers. This means certificates generated by this provider will be trusted by all major operating systems, web browsers, and devices.
Using this service, valid certificates can be generated to support custom domains on IBM Cloud.
domain validation
Let’s Encrypt needs to verify you control the domain before generating certificates.
During the verification process, the user makes an authentication token available through the domain. The service supports numerous methods for exposing the authentication token, including HTTP endpoints, DNS TXT records or TLS SNI.
There is an application (certbot) which automates generating authentication tokens and certificates.
I’m going to use the DNS TXT record as the challenge mechanism. Using this approach, certbot will provide a random authentication token I need to create as the TXT record value under the _acme-challenge.<YOUR_DOMAIN> sub-domain before validation.
I’m generating a wildcard certificate for any sub-domains under <YOUR_DOMAIN>. This allows me to use the same certificate with different sub-domains on IBM Cloud, rather than generating a certificate per sub-domain.
During the validation process, certbot should display the following message with the challenge token.
12345678
Please deploy a DNS TXT record under the name
_acme-challenge.<YOUR_DOMAIN> with the following value:
<CHALLENGE_TOKEN>
Before continuing, verify the record is deployed.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Press Enter to Continue
setting challenge token
Take the challenge token from certbot and create a new TXT record with this value for the _acme-challenge.<YOUR_DOMAIN> sub-domain.
Use the dig command to verify the TXT record is available.
1
dig -t txt _acme-challenge.<YOUR_DOMAIN>
The challenge token should be available in the DNS response shown by dig. 👍
12
;; ANSWER SECTION:
_acme-challenge.<YOUR_DOMAIN>. 3599 IN TXT "<CHALLENGE_TOKEN>"
Press Enter in the terminal session running certbot when the challenge token is available.
retrieving domain certificates
certbot will now retrieve the TXT record for the sub-domain and verify it matches the challenge token. If the domain has been validated, certbot will show the directory containing the newly created certificates.
1234567
IMPORTANT NOTES:
- Congratulations! Your certificate and chain have been saved at:
/etc/letsencrypt/live/<YOUR_DOMAIN>/fullchain.pem
Your key file has been saved at:
/etc/letsencrypt/live/<YOUR_DOMAIN>/privkey.pem
Your cert will expire on 2019-03-03.
...
certbot creates the following files.
cert.pem - public domain certificate
privkey.pem - private key for domain certificate
chain.pem - intermediate domain certificates
fullchain.pem - public and intermediate domain certificates in a single file.
Registering the domain with IBM Cloud will require the public, private and intermediate certificate files.
Registering Custom Domain with IBM Cloud
Certificates for custom domains in IBM Cloud are managed by the Certificate Manager service.
Check the “Region” selector matches the region chosen for your actions and APIs.
Click the ··· icon on the row where “Organisation” and “Space” values match your APIs.
Click ”Change Settings” from the pop-up menu.
domain validation
IBM Cloud now needs to verify you control the custom domain being used.
Another DNS TXT record needs to be created before attempting to bind the domain.
From the ”Custom Domain Settings” menu, make a note of the ”Default domain / alias” value. This should be in the format: <APP_ID>.<REGION>.apiconnect.appdomain.cloud.
Create a new TXT record for the custom sub-domain (api.<YOUR_DOMAIN>) with the default domain alias as the record value (<APP_ID>.<REGION>.apiconnect.appdomain.cloud).
Use the dig command to check the sub-domain TXT record exists and contains the correct value.
1
dig -t txt api.<YOUR_DOMAIN>
The default domain alias value should be available in the DNS response shown by dig. 👍
12
;; ANSWER SECTION:
api.<YOUR_DOMAIN>. 3599 IN TXT "<APP_ID>.<REGION>.apiconnect.appdomain.cloud"
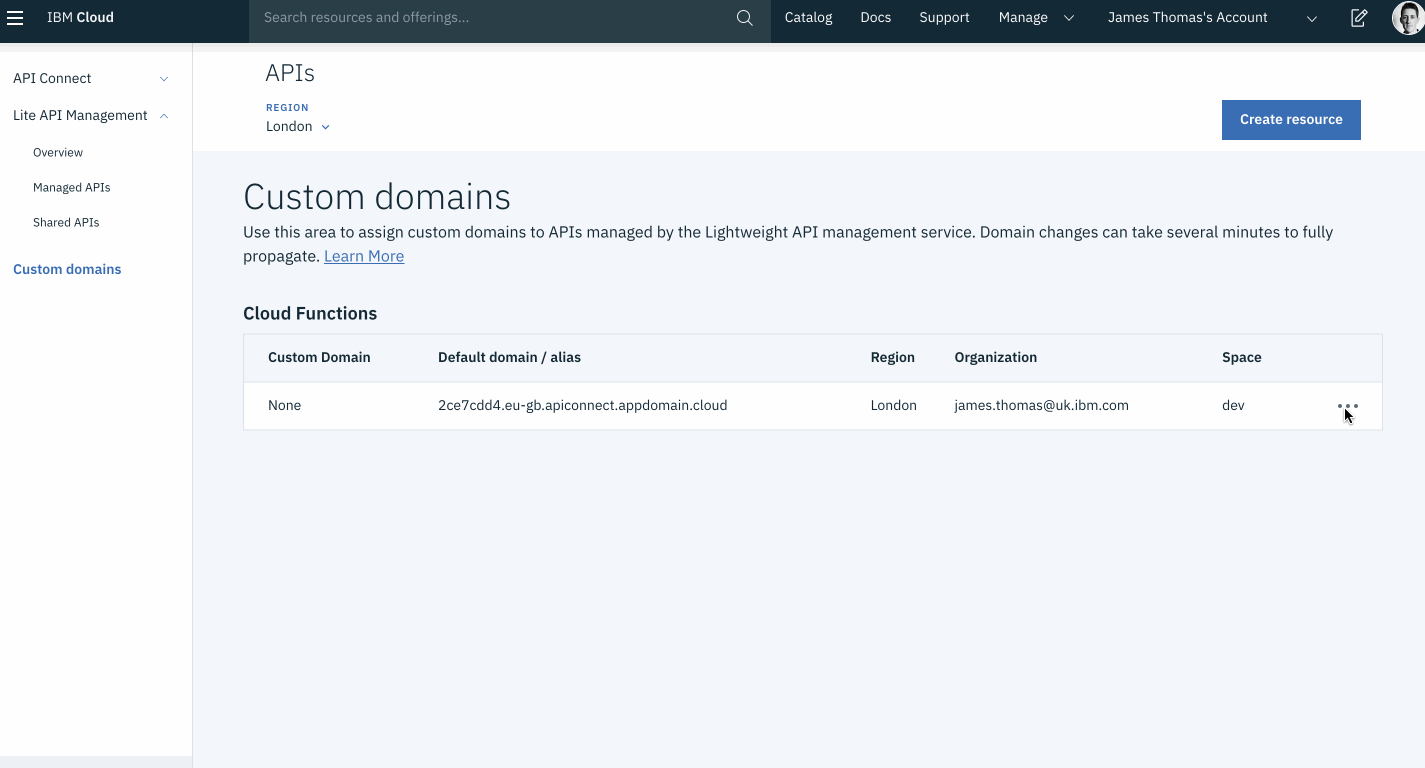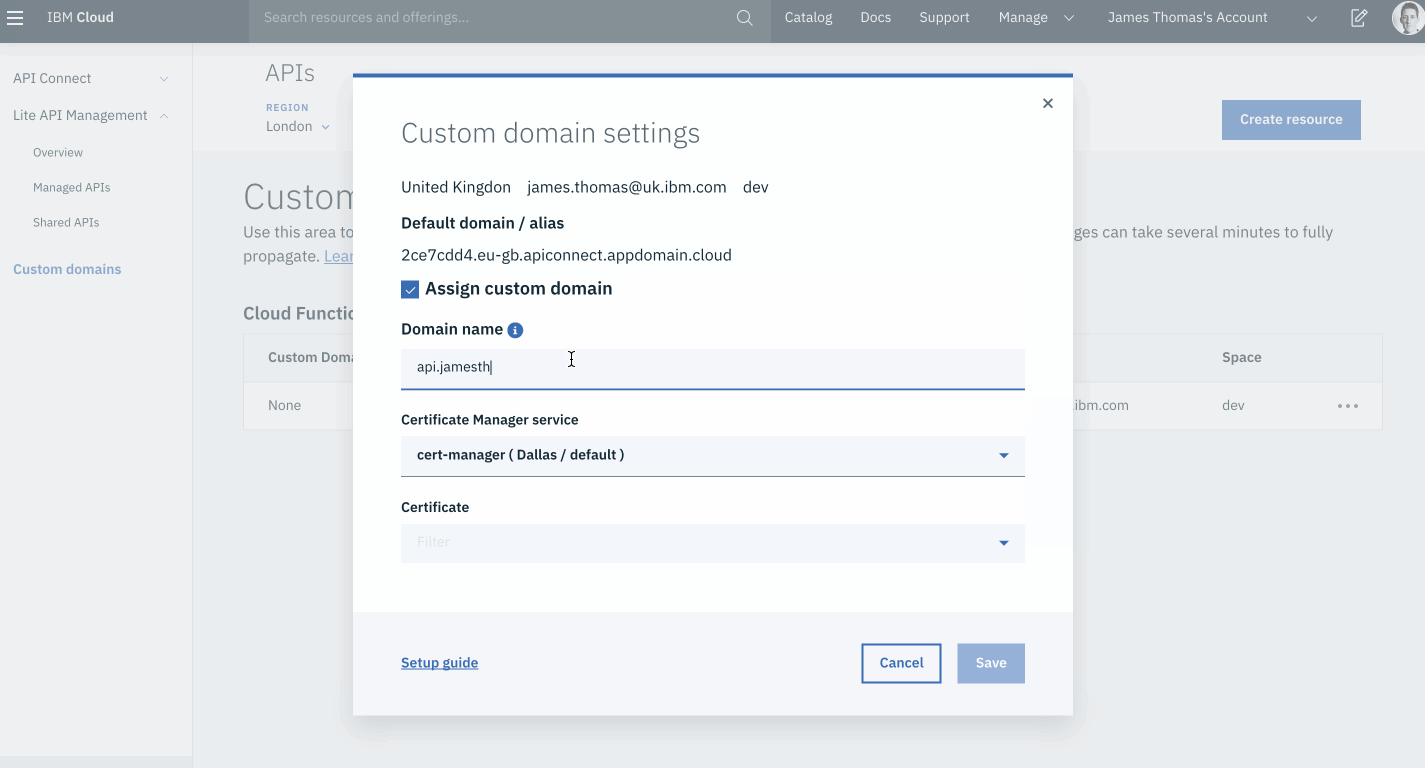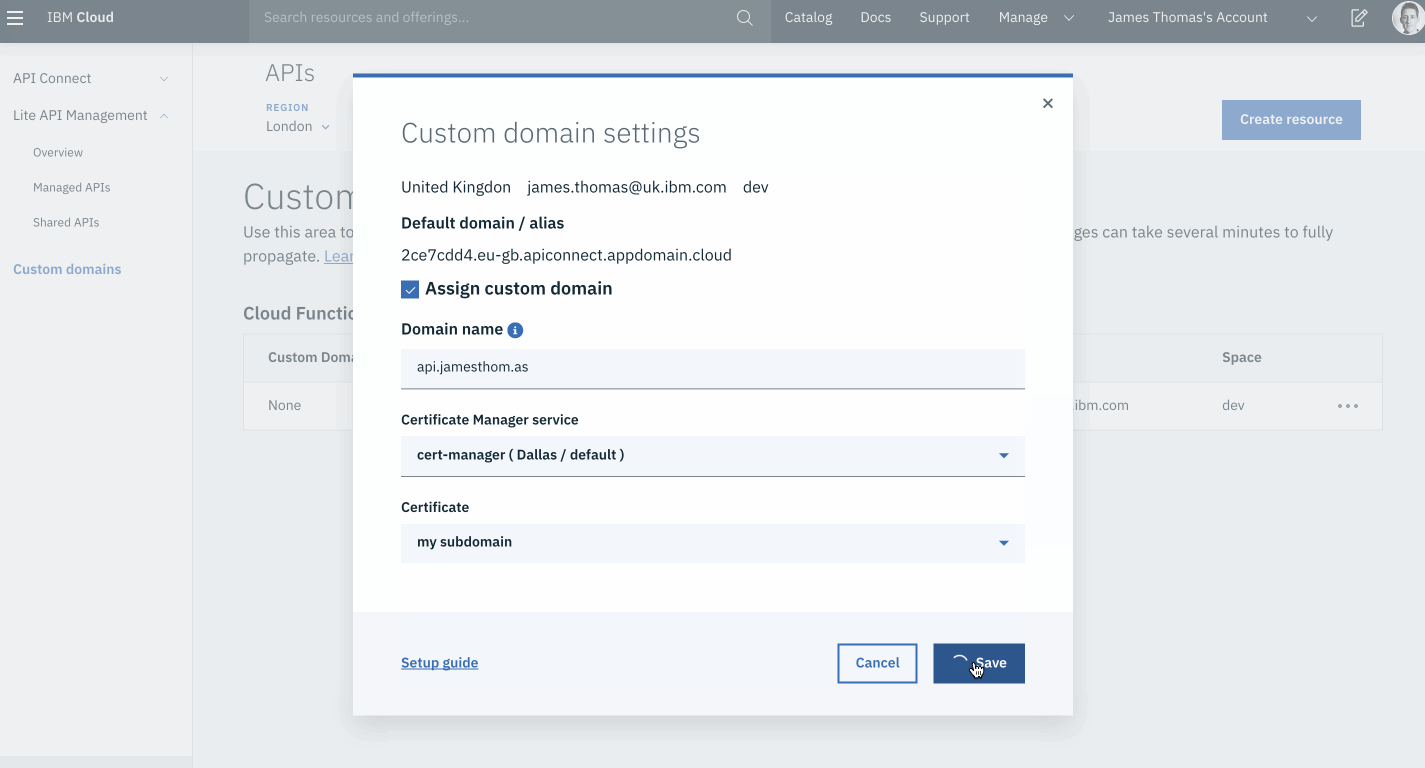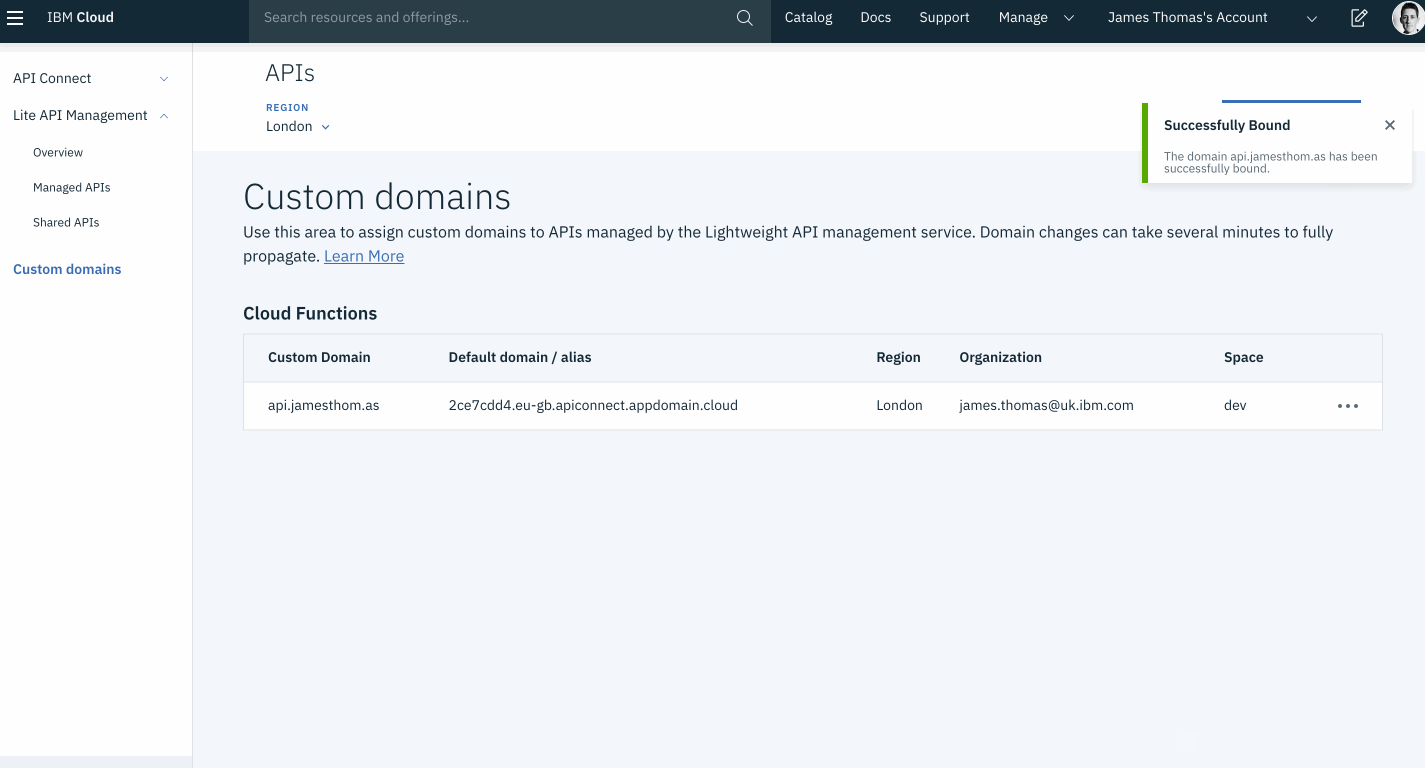
Having created the TXT record, fill in the Custom Domain Settings form.
custom domain settings
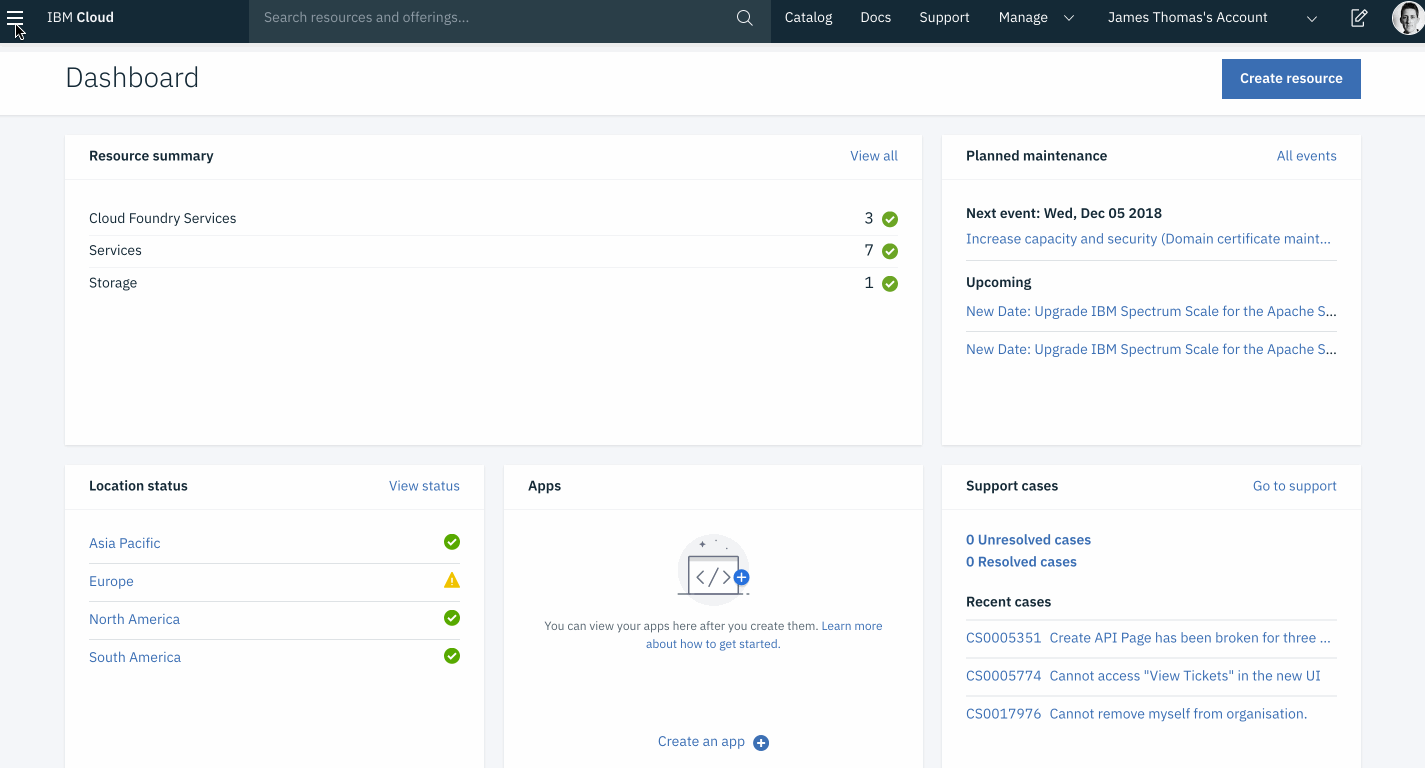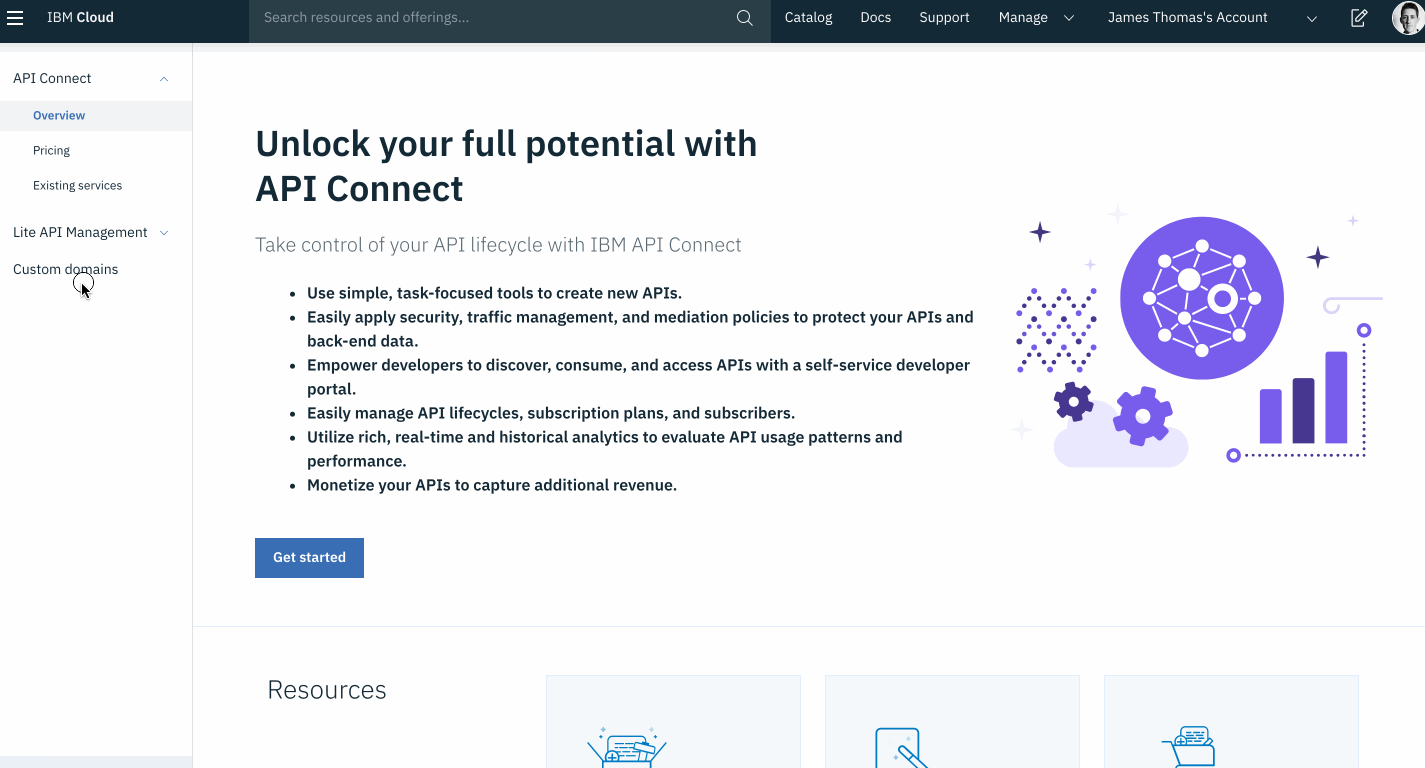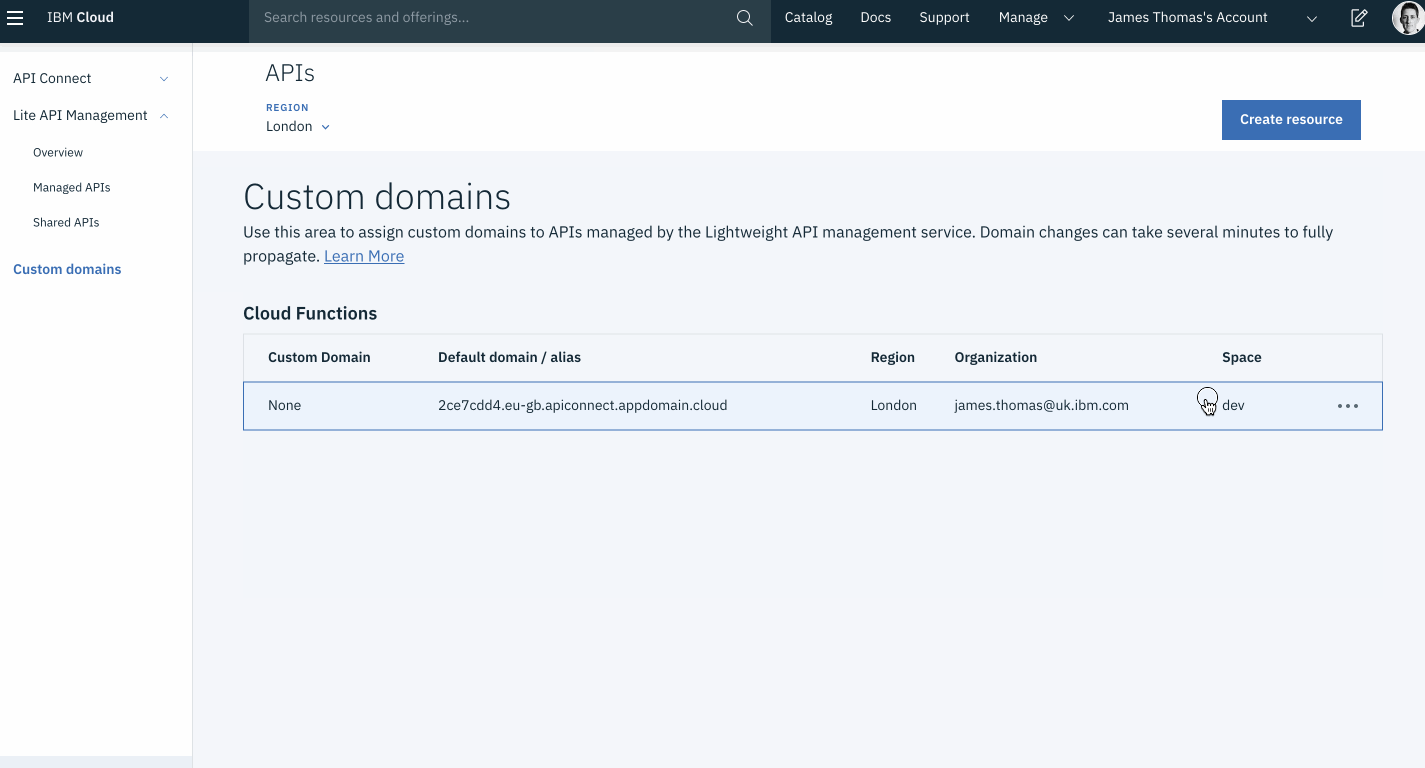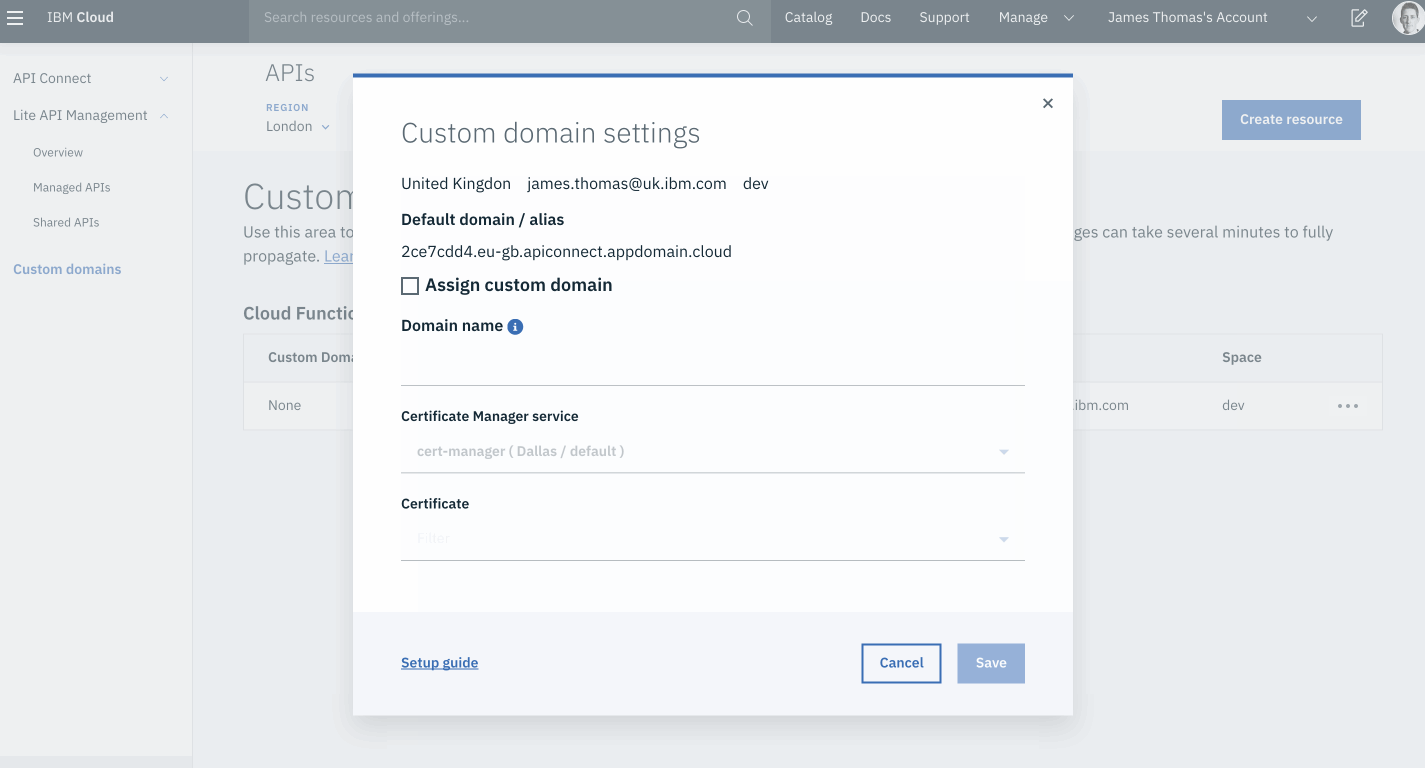
Select the ”Assign custom domain” checkbox in the ”Custom domain settings” form.
Fill in the following form fields.
Domain Name: use the custom sub-domain to bind (api.<YOUR-DOMAIN>).
Certificate Manager service: select the certificate manger instance.
Certificate: select the domain certificate from the drop-down menu.
Click the ”Save” button.
Once the domain has been validated, the form will redirect to the custom domains overview. The “Custom Domain” field will now show the sub-domain bound to the correct default domain alias.
add CNAME record
Remove the existing TXT record for the custom sub-domain (api.<YOUR-DOMAIN>).
Add a new CNAME record mapping the custom sub-domain (api.<YOUR-DOMAIN>) to the ”Default domain / alias” on IBM Cloud (<APP_ID>.<REGION>.apiconnect.appdomain.cloud).
Use the dig command to check the CNAME record is correct.
1
dig -t CNAME api.<YOUR_DOMAIN>
The default domain alias value should be available in the DNS response shown by dig. 👍
12
;; ANSWER SECTION:
api.<YOUR_DOMAIN>. 3599 IN CNAME <APP_ID>.<REGION>.apiconnect.appdomain.cloud.
Testing It Out
Functions should now be accessible through both the default domain alias and the new custom domain. 👏
Invoke the default domain alias API URL for the function.
As a developer advocate, I spend a lot of time at developer conferences (talking about serverless 😎). Upon returning from each trip, I need to compile a “trip report” on the event for my bosses. This helps demonstrate the value in attending events and that I’m not just accruing air miles and hotel points for fun… 🛫🏨
I always include any social media content people post about my talks in the trip report. This is usually tweets with photos of me on stage. If people are tweeting about your session, I assume they enjoyed it and wanted to share with their followers.
Finding tweets with photos about your talk from attendees is surprisingly challenging.
Attendees often forget to include your twitter username in their tweets. This means the only way to find those photos is to manually scroll through all the results from the conference hashtag. This is problematic at conferences with thousands of attendees all tweeting during the event. #devrelproblems.
Having become bored of manually trawling through all the tweets for each conference, I had a thought…
“Can’t I write some code to do this for me?”
This didn’t seem like too ridiculous an idea. Twitter has an API, which would allow me to retrieve all tweets for a conference hashtag. Once I had all the tweet photos, couldn’t I run some magic AI algorithm over the images to tell me if I was in them? 🤔
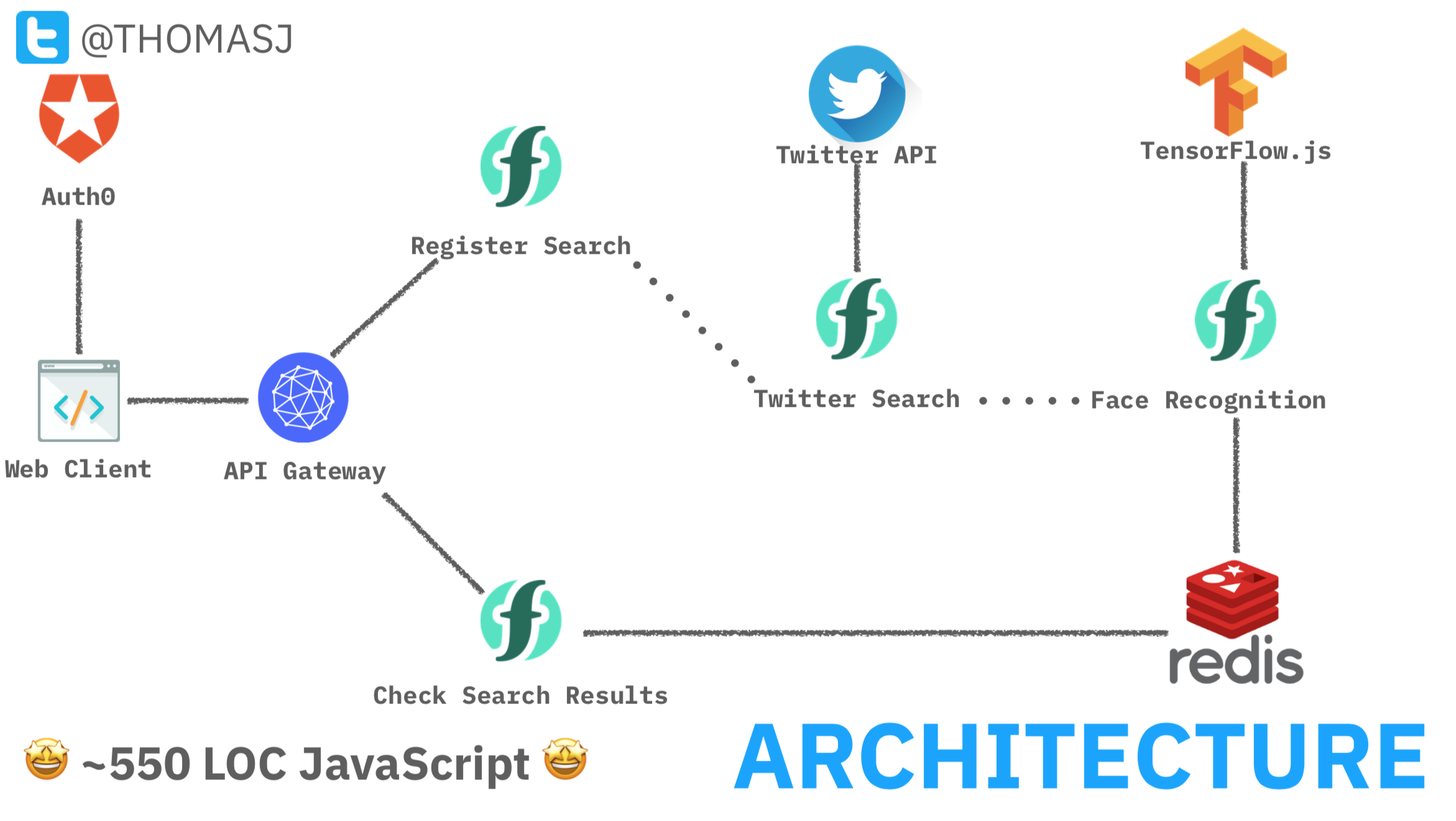
After a couple of weeks of hacking around (and overcoming numerous challenges) I had (to my own amazement) managed to build a serverless application which can find unlabelled photos of a person on twitter using machine learning with TensorFlow.js.
This application has four serverless functions (two API handlers and two backend services) and a client-side application from a static web page. Users log into the client-side application using Auth0 with their Twitter account. This provides the backend application with the user’s profile image and Twitter API credentials.
When the user invokes a search query, the client-side application invokes the API endpoint for the register_searchfunction with the query terms and twitter credentials. This function registers a new search job in Redis and fires a new search_request trigger event with the query and job id. This job identifier is returned to the client to poll for real-time status updates.
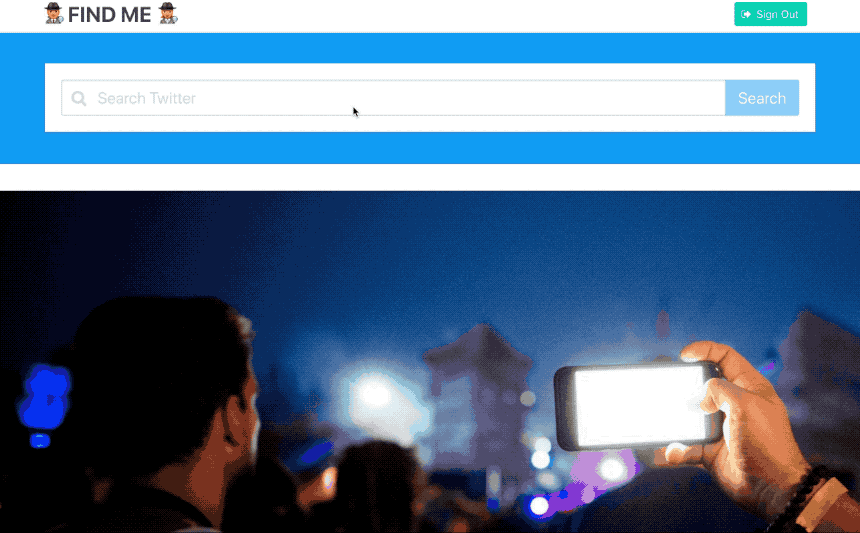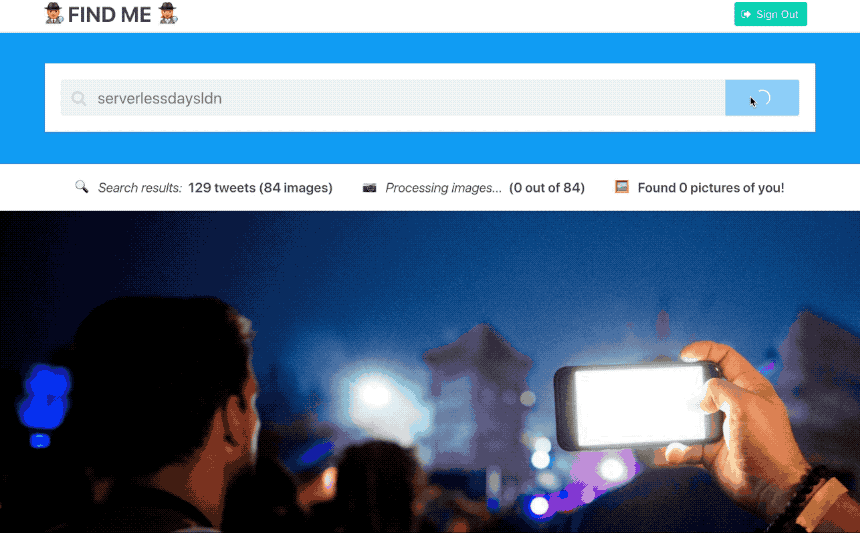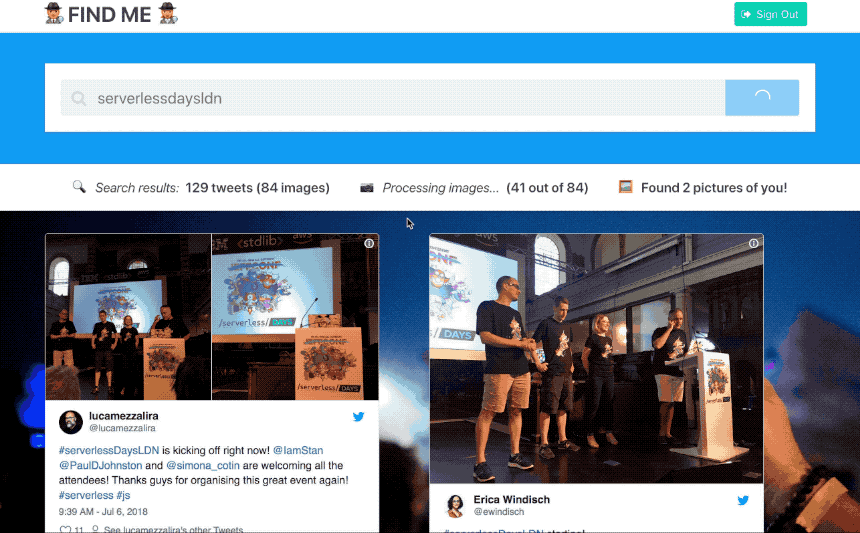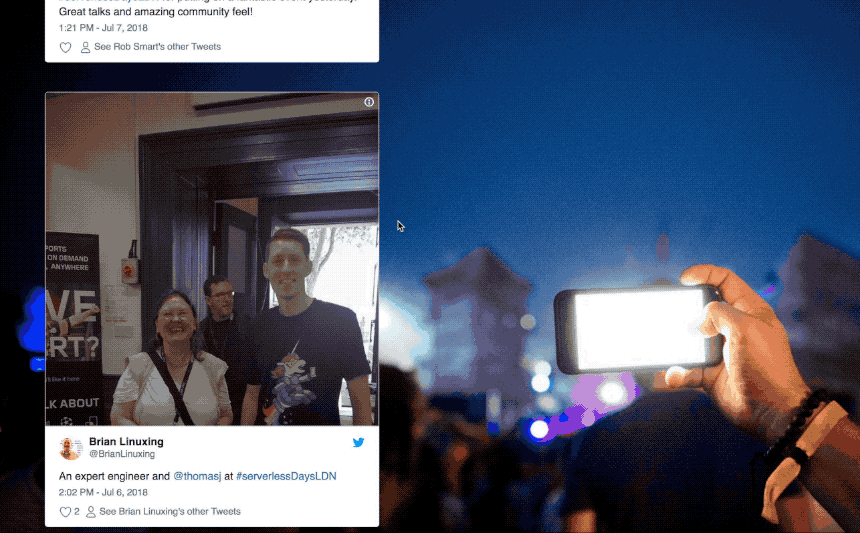
The twitter_searchfunction is connected to the search_request trigger and invoked for each event. It uses the Twitter Search API to retrieve all tweets for the search terms. If tweets retrieved from the API contain photos, those tweet ids (with photo urls) are fired as new tweet_image trigger events.
The compare_imagesfunction is connected to the tweet_image trigger. When invoked, it downloads the user’s twitter profile image along with the tweet image and runs face detection against both images, using the face-api.jslibrary. If any faces in the tweet photo match the face in the user’s profile image, tweet ids are written to Redis before exiting.
The client-side web page polls for real-time search results by polling the API endpoint for the search_statusfunction with the search job id. Tweets with matching faces are displayed on the web page using the Twitter JS library.
challenges
Since I had found an NPM library to handle face detection, I could just use this on a serverless platform by including the library within the zip file used to create my serverless application? Sounds easy, right?!
ahem - not so faas-t…. ✋
As discussed in previous blog posts, there are numerous challenges in using TF.js-based libraries on serverless platforms. Starting with making the packages available in the runtime and loading model files to converting images for classification, these libraries are not like using normal NPM modules.
Here are the main challenges I had to overcome to make this serverless application work…
using tf.js libraries on a serverless platform
The Node.js backend drivers for TensorFlow.js use a native shared C++ library (libtensorflow.so) to execute models on the CPU or GPU. This native dependency is compiled for the platform during the npm install process. The shared library file is around 142MB, which is too large to include in the deployment package for most serverless platforms.
Normal workarounds for this issue store large dependencies in an object store. These files are dynamically retrieved during cold starts and stored in the runtime filesystem, as shown in this pseudo-code. This workaround does add an additional delay to cold start invocations.
1234567891011
letcold_start=falseconstlibrary='libtensorflow.so'if(cold_start){constdata=from_object_store(library)write_to_fs(library,data)cold_start=true}// rest of function code…
Fortunately, I had a better solution using Apache OpenWhisk’s support for custom Docker runtimes!
This feature allows serverless applications to use custom Docker images as the runtime environment. Creating custom images with large libraries pre-installed means they can be excluded from deployment packages. 💯
Apache OpenWhisk publishes all existing runtime images on Docker Hub. Using existing runtime images as base images means Dockerfiles for custom runtimes are minimal. Here’s the Dockerfile needed to build a custom runtime with the TensorFlow.js Node.js backend drivers pre-installed.
The OpenWhisk provider plugin for The Serverless Framework also supports custom runtime images through a configuration parameter (image) under the function configuration.
Having fixed the issue of library loading on serverless platforms, I could move onto the next problem, loading the pre-trained models… 💽
loading pre-trained models
Running the example code to load the pre-trained models for face recognition gave me this error:
1
ReferenceError:fetch is not defined
In the previous blog post, I discovered how to manually load TensorFlow.js models from the filesystem using the file:// URI prefix. Unfortunately, the face-api.js library doesn’t support this feature. Models are automatically loaded using the fetch HTTP client. This HTTP client is available into modern browsers but not in the Node.js runtime.
Overcoming this issue relies on providing an instance of a compatible HTTP client in the runtime. The node-fetch library is a implementation of the fetch client API for the Node.js runtime. By manually installing this module and exporting as a global variable, the library can then use the HTTP client as expected.
12
// Make HTTP client available in runtimeglobal.fetch=require('node-fetch')
Model configuration and weight files can then be loaded from the library’s Github repository using this URL:
The face-api.js library has a utility function (models.allFaces) to automatically detect and calculate descriptors for all faces found in an image. Descriptors are a feature vector (of 128 32-bit float values) which uniquely describes the characteristics of a persons face.
The input to this function is the input tensor with the RGB values from an image. In a previous blog post, I explained how to convert an image from the filesystem in Node.js to the input tensor needed by the model.
Finding a user by comparing their twitter profile against photos from tweets starts by running face detection against both images. By comparing computed descriptor values, a measure of similarity can be established between faces from the images.
face comparison
Once the face descriptors have been calculated the library provides a utility function to compute the euclidian distance between two descriptors vectors. If the difference between two face descriptors is less than a threshold value, this is used to identify the same person in both images.
I’ve no idea why 0.6 is chosen as the threshold value but this seemed to work for me! Even small changes to this value dramatically reduced the precision and recall rates for my test data. I’m calling it the Goldilocks value, just use it…
performance
Once I had the end to end application working, I wanted to make it was fast as possible. By optimising the performance, I could improve the application responsiveness and reduce compute costs for my backend. Time is literally money with serverless platforms.
baseline performance
Before attempting to optimise my application, I needed to understand the baseline performance. Setting up experiments to record invocation durations gave me the following average test results.
Warm invocations: ~5 seconds
Cold invocations: ~8 seconds
Instrumenting the code with console.time statements revealed execution time was comprised of five main sections.
Cold Starts
Warm Starts
Initialisation
1200 ms
0 ms
Model Loading
3200 ms
2000 ms
Image Loading
500 ms x 2
500 ms x 2
Face Detection
700 ms - 900 ms x 2
700 ms - 900 ms x 2
Everything Else
1000 ms
500 ms
Total Duration
~ 8 seconds
~ 5 seconds
Initialisation was the delay during cold starts to create the runtime environment and load all the library files and application code. Model Loading recorded the time spent instantiating the TF.js models from the source files. Image Loading was the time spent converting the RGB values from images into input tensors, this happened twice, once for the twitter profile picture and again for the tweet photo. Face Detection is the elapsed time to execute the models.allFaces method and faceapi.euclideanDistance methods for all the detected faces. Everything else is well… everything else.
Since model loading was the largest section, this seemed like an obvious place to start optimising. 📈📉
loading model files from disk
Overcoming the initial model loading issue relied on manually exposing the expected HTTP client in the Node.js runtime. This allowed models to be dynamically loaded (over HTTP) from the external Github repository. Models files were about 36MB.
My first idea was to load these model files from the filesystem, which should be much faster than downloading from Github. Since I was already building a custom Docker runtime, it was a one-line change to include the model files within the runtime filesystem.
Having re-built the image and pushed to Docker Hub, the classification function’s runtime environment now included models files in the filesystem.
But how do we make the face-api.js library load models files from the filesystem when it is using a HTTP client?
My solution was to write a fetch client that proxied calls to retrieve files from a HTTP endpoint to the local filesystem. 😱 I’d let you decide whether this is a brilliant or terrible idea!
The face-api.js library only used two methods (json() & arrayBuffer()) from the HTTP client. Stubbing out these methods to proxy fs.readFileSync meant files paths were loaded from the filesystem. Amazingly, this seemed to just work, hurrah!
Implementing this feature and re-running performance tests revealed this optimisation saved about 500 ms from the Model Loading section.
Cold Starts
Warm Starts
Initialisation
1200 ms
0 ms
Model Loading
2700 ms
1500 ms
Image Loading
500 ms x 2
500 ms x 2
Face Detection
700 ms - 900 ms x 2
700 ms - 900 ms x 2
Everything Else
1000 ms
500 ms
Total Duration
~ 7.5 seconds
~ 4.5 seconds
This was less of an improvement than I’d expected. Parsing all the model files and instantiating the internal objects was more computationally intensive than I realised. This performance improvement did improve both cold and warm invocations, which was a bonus.
Despite this optimisation, model loading was still the largest section in the classification function…
caching loaded models
There’s a good strategy to use when optimising serverless functions…
Serverless runtimes re-use runtime containers for consecutive requests, known as warm environments. Using local state, like global variables or the runtime filesystem, to cache data between requests can be used to improve performance during those invocations.
Since model loading was such an expensive process, I wanted to cache initialised models. Using a global variable, I could control whether to trigger model loading or return the pre-loaded models. Warm environments would re-use pre-loaded models and remove model loading delay.
This performance improvement had a significant impact of the performance for warm invocations. Model loading became “free”. 👍
Cold Starts
Warm Starts
Initialisation
1200 ms
0 ms
Model Loading
2700 ms
0 ms
Image Loading
500 ms x 2
500 ms x 2
Face Detection
700 ms - 900 ms x 2
700 ms - 900 ms x 2
Everything Else
1000 ms
500 ms
Total Duration
~ 7.5 seconds
~ 3 seconds
caching face descriptors
In the initial implementation, the face comparison function was executing face detection against both the user’s twitter profile image and tweet photo for comparison. Since the twitter profile image was the same in each search request, running face detection against this image would always return the same results.
Rather than having this work being redundantly computed in each function, caching the results of the computed face descriptor for the profile image meant it could re-used across invocations. This would reduce by 50% the work necessary in the Image & Model Loading sections.
The face-api.js library returns the face descriptor as a typed array with 128 32-bit float values. Encoding this values as a hex string allows them to be stored and retrieved from Redis. This code was used to convert float values to hex strings, whilst maintaining the exact precision of those float values.
This optimisation improves the performance of most cold invocations and all warm invocations, removing over 1200 ms of computation time to compute the results.
Cold Starts (Cached)
Warm Starts
Initialisation
1200 ms
0 ms |
Model Loading
2700 ms
1500 ms |
Image Loading
500 ms
500 ms |
Face Detection
700 ms - 900 ms
700 ms - 900 ms |
Everything Else
1000 ms
500 ms |
Total Duration
~ 6 seconds
~ 2.5 seconds |
Cold Starts
Warm Starts
Initialisation
1200 ms
0 ms
Model Loading
2700 ms
0 ms
Image Loading
500 ms
500 ms
Face Detection
700 ms - 900 ms
700 ms - 900 ms
Everything Else
1000 ms
500 ms
Total Duration
~ 7.5 seconds
~ 3 seconds
final results + cost
Application performance was massively improved with all these optimisations. As demonstrated in the video above, the application could process tweets in real-time, returning almost instant results. Average invocation durations were now.
Warm invocations: ~2.5 seconds
Cold invocations (Cached): ~6 seconds
Serverless platforms charge for compute time by the millisecond, so these improvements led to cost savings of 25% for cold invocations (apart the first classification for a user) and 50% for warm invocations.
Classification functions used 512MB of RAM which meant IBM Cloud Functions would provide 320,000 “warm” classifications or 133,333 “cold” classifications within the free tier each month. Ignoring the free tier, 100,000 “warm” classifications would cost $5.10 and 100,000 “cold” classifications $2.13.
conclusion
Using TensorFlow.js with serverless cloud platforms makes it easy to build scalable machine learning applications in the cloud. Using the horizontal scaling capabilities of serverless platforms, thousands of model classifications can be ran in parallel. This can be more performant than having dedicated hardware with a GPU, especially with compute costs for serverless applications being so cheap.
TensorFlow.js is ideally suited to serverless application due to the JS interface, (relatively) small library size and availability of pre-trained models. Despite having no prior experience in Machine Learning, I was able to use the library to build a face recognition pipeline, processing 100s of images in parallel, for real-time results. This amazing library opens up machine learning to a whole new audience!
Once I had this working with a local Node.js script, my next idea was to convert it into a serverless function. Running this function on IBM Cloud Functions (Apache OpenWhisk) would turn the script into my own visual recognition microservice.
Sounds easy, right? It’s just a JavaScript library? So, zip it up and away we go… ahem 👊
Converting the image classification script to run in a serverless environment had the following challenges…
TensorFlow.js libraries need to be available in the runtime.
Native bindings for the library must be compiled against the platform architecture.
Models files need to be loaded from the filesystem.
Some of these issues were more challenging than others to fix! Let’s start by looking at the details of each issue, before explaining how Docker support in Apache OpenWhisk can be used to resolve them all.
Challenges
TensorFlow.js Libraries
TensorFlow.js libraries are not included in the Node.js runtimes provided by the Apache OpenWhisk.
External libraries can be imported into the runtime by deploying applications from a zip file. Custom node_modules folders included in the zip file will be extracted in the runtime. Zip files are limited to a maximum size of 48MB.
Library Size
Running npm install for the TensorFlow.js libraries used revealed the first problem… the resulting node_modules directory was 175MB. 😱
Looking at the contents of this folder, the tfjs-node module compiles a native shared library (libtensorflow.so) that is 135M. This means no amount of JavaScript minification is going to get those external dependencies under the magic 48 MB limit. 👎
Native Dependencies
The libtensorflow.so native shared library must be compiled using the platform runtime. Running npm install locally automatically compiles native dependencies against the host platform. Local environments may use different CPU architectures (Mac vs Linux) or link against shared libraries not available in the serverless runtime.
MobileNet Model Files
TensorFlow models files need loading from the filesystem in Node.js. Serverless runtimes do provide a temporary filesystem inside the runtime environment. Files from deployment zip files are automatically extracted into this environment before invocations. There is no external access to this filesystem outside the lifecycle of the serverless function.
Models files for the MobileNet model were 16MB. If these files are included in the deployment package, it leaves 32MB for the rest of the application source code. Although the model files are small enough to include in the zip file, what about the TensorFlow.js libraries? Is this the end of the blog post? Not so fast….
Apache OpenWhisk’s support for custom runtimes provides a simple solution to all these issues!
Custom Runtimes
Apache OpenWhisk uses Docker containers as the runtime environments for serverless functions (actions). All platform runtime images are published on Docker Hub, allowing developers to start these environments locally.
Developers can also specify custom runtime images when creating actions. These images must be publicly available on Docker Hub. Custom runtimes have to expose the same HTTP API used by the platform for invoking actions.
Using platform runtime images as parent images makes it simple to build custom runtimes. Users can run commands during the Docker build to install additional libraries and other dependencies. The parent image already contains source files with the HTTP API service handling platform requests.
TensorFlow.js Runtime
Here is the Docker build file for the Node.js action runtime with additional TensorFlow.js dependencies.
12345
FROM openwhisk/action-nodejs-v8:latest
RUN npm install @tensorflow/tfjs @tensorflow-models/mobilenet @tensorflow/tfjs-node jpeg-js
COPY mobilenet mobilenet
openwhisk/action-nodejs-v8:latest is the Node.js action runtime image published by OpenWhisk.
TensorFlow libraries and other dependencies are installed using npm install in the build process. Native dependencies for the @tensorflow/tfjs-node library are automatically compiled for the correct platform by installing during the build process.
Since I’m building a new runtime, I’ve also added the MobileNet model files to the image. Whilst not strictly necessary, removing them from the action zip file reduces deployment times.
Once the image is available on Docker Hub, actions can be created using that runtime image. 😎
Example Code
This source code implements image classification as an OpenWhisk action. Image files are provided as a Base64 encoded string using the image property on the event parameters. Classification results are returned as the results property in the response.
Caching Loaded Models
Serverless platforms initialise runtime environments on-demand to handle invocations. Once a runtime environment has been created, it will be re-used for further invocations with some limits. This improves performance by removing the initialisation delay (“cold start”) from request processing.
Applications can exploit this behaviour by using global variables to maintain state across requests. This is often use to cache opened database connections or store initialisation data loaded from external systems.
I have used this pattern to cache the MobileNet model used for classification. During cold invocations, the model is loaded from the filesystem and stored in a global variable. Warm invocations then use the existence of that global variable to skip the model loading process with further requests.
Caching the model reduces the time (and therefore cost) for classifications on warm invocations.
Memory Leak
Running the Node.js script from blog post on IBM Cloud Functions was possible with minimal modifications. Unfortunately, performance testing revealed a memory leak in the handler function. 😢
TensorFlow.js’s Node.js extensions use a native C++ library to execute the Tensors on a CPU or GPU engine. Memory allocated for Tensor objects in the native library is retained until the application explicitly releases it or the process exits. TensorFlow.js provides a dispose method on the individual objects to free allocated memory. There is also a tf.tidy method to automatically clean up all allocated objects within a frame.
Reviewing the code, tensors were being created as model input from images on each request. These objects were not disposed before returning from the request handler. This meant native memory grew unbounded. Adding an explicit dispose call to free these objects before returning fixed the issue.
Profiling & Performance
Action code records memory usage and elapsed time at different stages in classification process.
Recording memory usage allows me to modify the maximum memory allocated to the function for optimal performance and cost. Node.js provides a standard library API to retrieve memory usage for the current process. Logging these values allows me to inspect memory usage at different stages.
Timing different tasks in the classification process, i.e. model loading, image classification, gives me an insight into how efficient classification is compared to other methods. Node.js has a standard library API for timers to record and print elapsed time to the console.
Demo
Deploy Action
Run the following command with the IBM Cloud CLI to create the action.
Replace <IMAGE_NAME> with the public Docker Hub image identifier for the custom runtime. Use jamesthomas/action-nodejs-v8:tfjs if you haven’t built this manually.
main is the total elapsed time for the action handler. mn_model.classify is the elapsed time for the image classification. Cold start requests print an extra log message with model loading time, loadModel: 394.547ms.
Performance Results
Invoking the classify action 1000 times for both cold and warm activations (using 256MB memory) generated the following performance results.
warm invocations
Classifications took an average of 316 milliseconds to process when using warm environments. Looking at the timing data, converting the Base64 encoded JPEG into the input tensor took around 100 milliseconds. Running the model classification task was in the 200 - 250 milliseconds range.
cold invocations
Classifications took an average of 1260 milliseconds to process when using cold environments. These requests incur penalties for initialising new runtime containers and loading models from the filesystem. Both of these tasks took around 400 milliseconds each.
One disadvantage of using custom runtime images in Apache OpenWhisk is the lack of pre-warmed containers. Pre-warming is used to reduce cold start times by starting runtime containers before they are needed. This is not supported for non-standard runtime images.
classification cost
IBM Cloud Functions provides a free tier of 400,000 GB/s per month. Each further second of execution is charged at $0.000017 per GB of memory allocated. Execution time is rounded up to the nearest 100ms.
If all activations were warm, a user could execute more than 4,000,000 classifications per month in the free tier using an action with 256MB. Once outside the free tier, around 600,000 further invocations would cost just over $1.
If all activations were cold, a user could execute more than 1,2000,000 classifications per month in the free tier using an action with 256MB. Once outside the free tier, around 180,000 further invocations would cost just over $1.
Conclusion
TensorFlow.js brings the power of deep learning to JavaScript developers. Using pre-trained models with the TensorFlow.js library makes it simple to extend JavaScript applications with complex machine learning tasks with minimal effort and code.
Getting a local script to run image classification was relatively simple, but converting to a serverless function came with more challenges! Apache OpenWhisk restricts the maximum application size to 50MB and native libraries dependencies were much larger than this limit.
Fortunately, Apache OpenWhisk’s custom runtime support allowed us to resolve all these issues. By building a custom runtime with native dependencies and models files, those libraries can be used on the platform without including them in the deployment package.