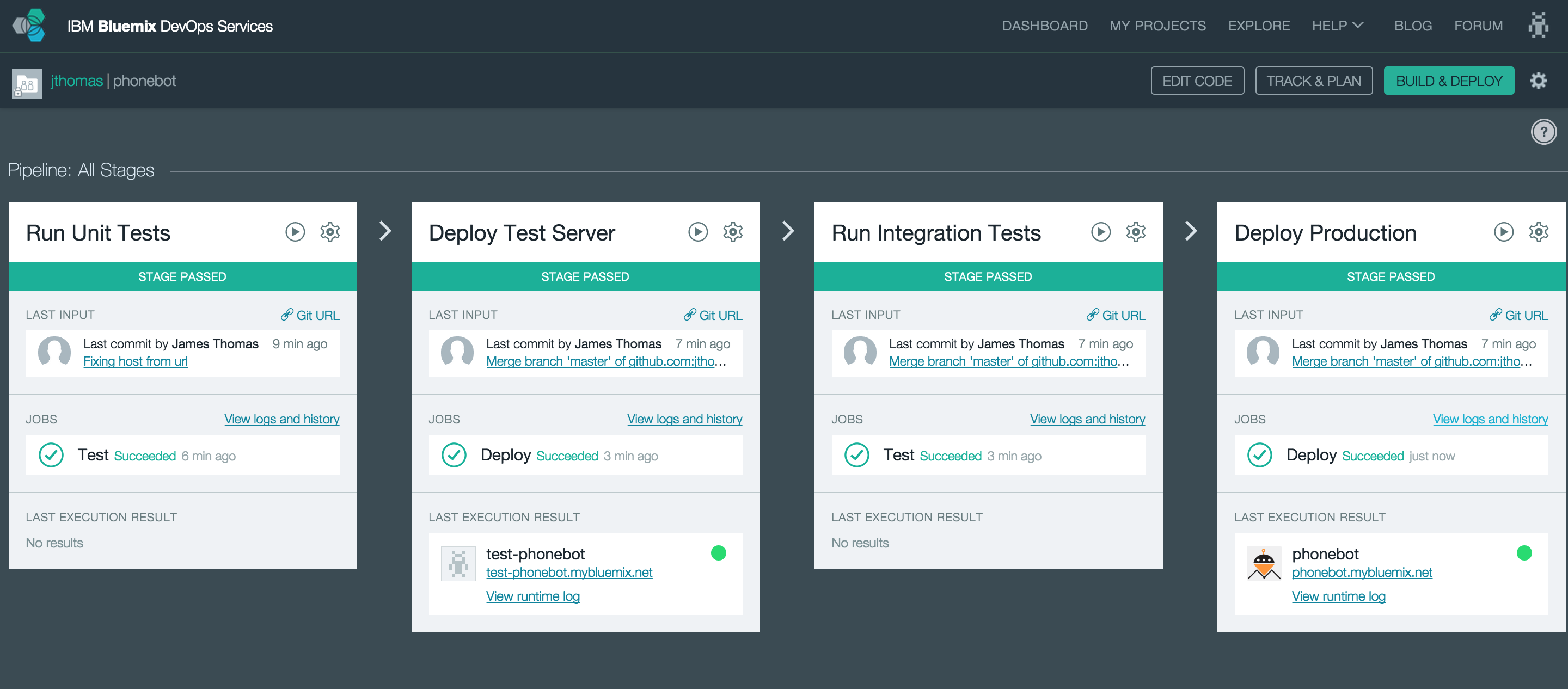
Whether making changes to a database schema, bulk importing data to initialise a database or setting up a connected service, there are often administrative tasks that needed to be carried out for an application to run correctly.
These tasks usually need finishing before starting the application and should not be executed more than once.
Previously, the CF CLI provided commands, tunnel and console, to help running one-off tasks manually. These commands were deprecated with the upgrade from v5 to v6 to discourage snowflake environments.
It is still possible, with a bit of hacking, to run one-off tasks manually from the application container.
A better way is to describe tasks as code and run them automatically during normal deployments. This results in applications that can be recreated without manual intervention.
We’ll look at both options before introducing a new library, oneoff, that automates running administration tasks for Node.js applications.
Running Tasks Manually
Local Environment
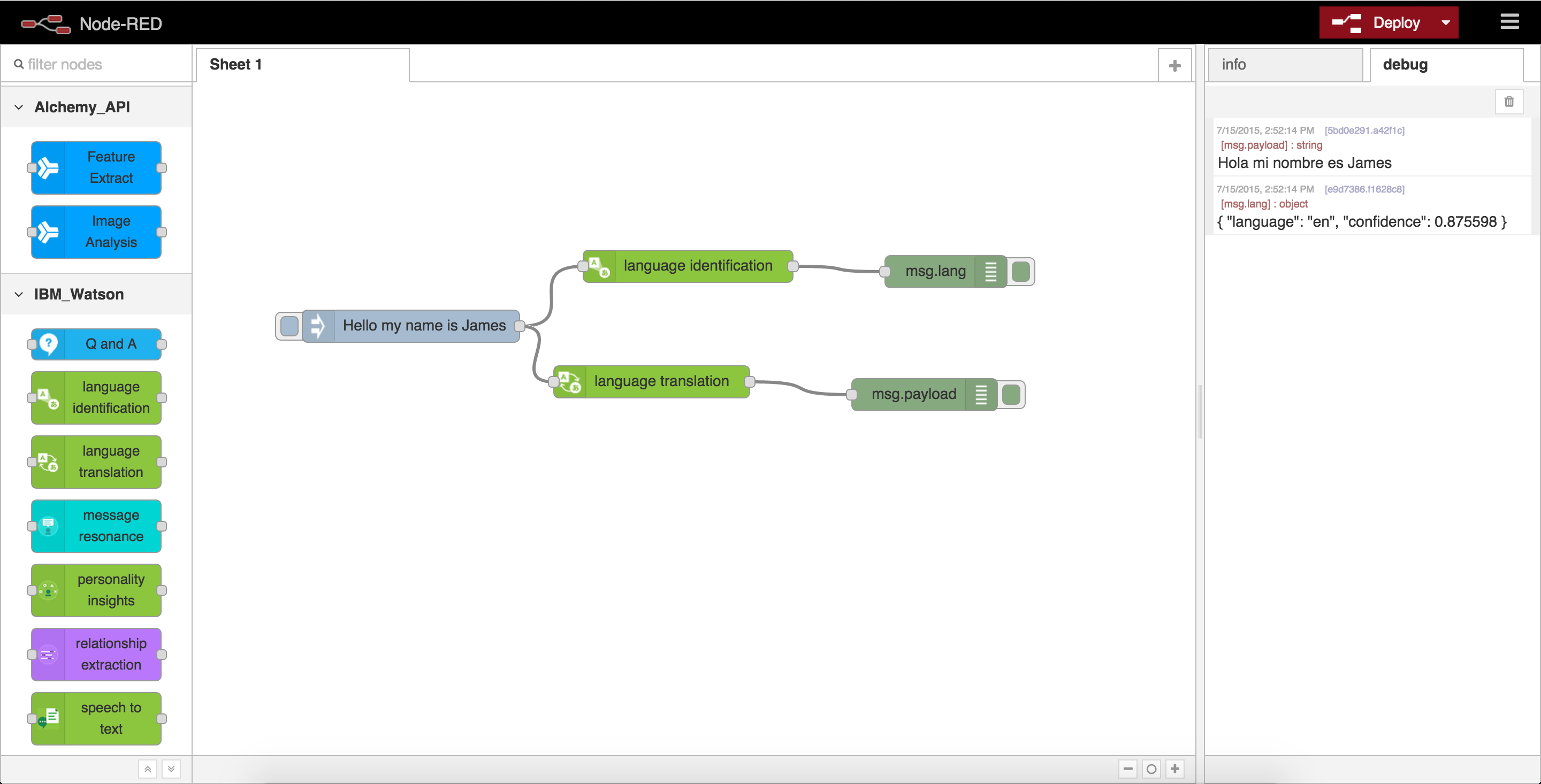
Rather than running administrative tasks from the application console, we can run them from a local development environment by remotely connecting to the bound services.
This will be dependent on the provisioned services allowing remote access. Many “built-in” platform services, e.g. MySQL, Redis, do not allow this.
Third-party services generally do.
Using the cf env command we can list service credentials for an application. These authentication details can often be used locally by connecting through a client library running in a local development environment.
For example, to access a provisioned Cloudant instance locally, we can grab the credentials and use with a Node.js client library.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
Remote Environment
When provisioned services don’t allow external access, the cf-ssh project creates SSH access to application containers running within Cloud Foundry.
How does this work?!
cf-ssh deploys a new Cloud Foundry application, containing the same bits as your target application, with the same bound services.
This new application’s container does not start your web application as per normal. Instead, it starts an outbound reverse SSH tunnel to a public proxy.
The local cf-ssh client then launches an interactive ssh connect to the public proxy, which tunnels through to the application container.
See the explanation here for full details.
This approach will let you connect to services from within the Cloud Foundry platform environment.
This video from Stark & Wayne’s Dr. Nic shows the command in action…
IBM Bluemix Console (Java and Node.js)
This technique is only for the IBM Bluemix platform.
If you are deploying Node.js and Java applications on IBM Bluemix, the platform provides the following tools to assist with application management.
- proxy: Minimal application management that serves as a proxy between your application and Bluemix.
- devconsole: Enables the development console utility.
- shell: Enables a web-based shell.
- trace: (Node.js only) Dynamically set trace levels if your application is using log4js, ibmbluemix, or bunyan logging modules.
- inspector: (Node.js only) Enables node inspector debugger.
- debug: (Liberty only) Enables clients to establish a remote debugging session with the application.
- jmx: (Liberty only) Enables the JMX REST Connector to allow connections from remote JMX clients
The tools are enabled by setting the environment variable (BLUEMIX_APP_MGMT_ENABLE) with the desired utilities.
1
| |
Applications must be restarted for the changes to take effect.
If we enable the shell utility, the following web-based console will be available at https://your-app-name.mybluemix.net/bluemix-debug/shell.

Cloud Foundry Diego Runtime
Diego is the next-generation runtime that will power upcoming versions of Cloud Foundry. Diego will provide many benefits over the existing runtime, e.g. Docker support, including enabling SSH access to containers without the workarounds needed above.
Yay!
Follow the instructions here for details on SSH access to applications running on the new runtime.
Access to this feature will be dependent on your Cloud Foundry provider migrating to the new runtime.
Running Tasks Automatically
Manually running one-off administrative tasks for Cloud Foundry applications is a bad idea.
It affects your ability to do continuous delivery and encourages snowflake environments.
Alternatively, defining tasks as code means they can run automatically during normal deployments. No more manual steps are required to deploy applications.
There are many different libraries for every language to help you programmatically define, manage and run tasks.
With tasks defined as code, you need to configure your application manifest to run these automatically during deployments.
Cloud Foundry uses the command parameter, set in the manifest or through the command-line, to allow applications to specify a custom start command. We can use this parameter to execute the task library command during deployment.
The Cloud Foundry documentation also details these approaches, with slightly different implementations here and specifically for Ruby developers here.
Temporary Task Deploy
For applications which only need occasional administrative tasks, it’s often easier to push a temporary deploy with a custom start command. This deploy runs your tasks without then starting your application. Once the tasks have completed, redeploy your application normally, destroying the task instance.
The following command will deploy a temporary instance for this purpose:
1
| |
We’re overriding the default start command, setting it to run the command for our task library, e.g. rake db:migrate.
The sleep infinity command stops the application exiting once the task runner has finished. If this happens, the platform will assume that application has crashed and restart it.
Also, the task runner will not be binding to a port so we need to use the –no-route argument to stop the platform assuming the deploy has timed out.
Setting the deploy to a single instance stops the command being executed more than once.
Checking the logs to verify the task runner has finished correctly, we can now redeploy our application. Using the null start command will force the platform to use the buildpack default rather than our previous option.
1
| |
Running Tasks Before Startup
If we’re regularly running administrative tasks, we should incorporate the task execution into our normal application startup. Once the task command has finished successfully, we start the application as normal.
Applications may have multiple instances running, we need to ensure the tasks are only executed by one instance.
The following custom start command will execute tasks during startup, using the CF_INSTANCE_ID environment variable to enforce execution at most-once.
[ $CF_INSTANCE_INDEX -eq 0 ]] && node lib/tasks/runner.js; node app.js
With this approach, tasks will be automatically executed during regular deployments without any manual intervention.
Hurrah!
Managing tasks for Node.js applications
If you’re running Node.js applications on Cloud Foundry, oneoff is a task library that helps you define tasks as code and integrates with the Cloud Foundry runtime. The module handles all the complexities with automating tasks during deployments across multi-instance applications.
oneoff provides the following features…
* ensure tasks are completed before application startup
* coordinating app instances to ensure at-most once task execution
* automagically discovering tasks from the task directory
* dependency ordering, ensure task a completes before task b starts
* parallel task execution
* ignore completed tasks in future deployments
Check it out to help make writing tasks as code for Node.js applications much easier!
Full details on usage are available in the README.
Conclusion
Running one-off tasks for application configuration is a normal part of any development project.
Carrying out these tasks manually used to be the norm, but with the devops movement we now prefer automated configuration rather manual intervention. Relying on manual configuration steps to deploy applications restricts our ability to implement continuous delivery.
Cloud Foundry is an opinionated platform, actively discouraging the creation of snowflake environments.
Whilst it is still possible to manually run administrative tasks, either by connecting to bound services locally or using a remote console, it’s preferable to describe our tasks as code and let the platform handle it.
Using custom start commands, we can deploy applications which run tasks automatically during their normal startup procedure.